Appearance
Tops
Overview
This page starts off very wordy, sorry about that. Feel free to skip down to the examples section if you just want hips vs my ramblings.
A huge problem with Tops is terminology, documentation, workflow. Lops was in a similar boat, but at least that had the excuse of deriving from USD and having to stick to those concepts.
That said in December 2020 I had that 'click' moment. I've been able to do some complex work setups that would be difficult or impossible without Tops. It was a good time to update these notes, try and explain tops in terms Houdini artists can understand. If any of it isn't clear (or better, if you have fixes for my mistakes), let me know!
What is Tops, superfast tech summary
Tops creates variables (like hscript vars) that can be used to drive other nodes. Tops can also start many hython jobs in parallel, each one running whatever process you ask it to (mantra, a sim cache, ffmpeg, shotgun etc), and give you a gui to track all this.
That's a very dry summary, but it important to keep these fairly simple core concepts in mind. Tops attributes, and lots of hython under the hood to do work.
Variables? Attributes?
To drill down on that a little more, you might be used to putting $T or @Frame into sops parameters to do things, or $OS and $HIP elsewhere. Tops nodes create attributes for each bit of work you want to do, say @pdg_input to represent filenames, or @rbd_vel for a wedged velocity. If you refer to that elsewhere, in exactly the same way you'd use $OS or $T, tops now 'controls' that parameter, and will change what that value represents for each unit of work. This is the core of how Tops interacts with the rest of Houdini, so its important to understand that early!
Tops vs Rops, obj vs sops, vs farms
Tops is a node graph for tasks and processes. It's similar to Rops in that it lets you chain operations together and control execution order. A major difference between Rops and Tops is fine grain control. Layering analogies, Rops compared to Tops is like /obj compared to Sops.
- /obj is a container based view of things, you don't see what's going on inside the nodes, and it has a limited set of nodes
- Rops is a container based view of rendering, you don't see whats going on inside the nodes, it has a limited set of nodes
vs
- Sops is an atomic view of things, you can get right down to the points, it's much more general in scope
- Tops is an atomic view of tasks and processing, you can get right down to the frames/individual processes, it's much more general in scope
Because Tops has more awareness of what each node is doing, it can do things that would be difficult with rops or standard renderfarm software. Eg:
- ensure things are run in parallel as much as possible
- never have tasks waiting unnecessarily
- use as many cpu cores as you have
- detect when tasks don't need to be re-run, skip over them
- when connected to a farm, allow complex control over many machines doing many tasks
- put a simple gui on simple operations
- provide a full python api for complex operations
- has built in support to control other apps, eg maya, nuke, ffmpeg
- has built in support to talk to asset management systems like shotgun
- has built in support to work with tractor, deadline, hqueue
Some of those features work great, others feel a little early and rough, but the potential is there.
Workitems vs points
If going from /obj to sops lets you play with points, going from rops to tops lets you play with workitems, the atomic unit of tops. At its simplest you can think of a workitem as a frame. If a mantra top renders frames 1 to 100, you'll see 100 workitems in the GUI, represented as little dots.

Workitems can be many things
 Workitems are more than just frames of a render. In a similar way that a point in sops can represent a particle, a vertex of a shape, a packed primitive, an RBD object, a workitem could be:
Workitems are more than just frames of a render. In a similar way that a point in sops can represent a particle, a vertex of a shape, a packed primitive, an RBD object, a workitem could be:
- a frame of a render
- an entire image sequence
- the location of a mp4 on disk
- an asset name
- whatever you want it to be
Workitems can be collapsed into partitions if you need that, and expanded out again later into individual workitems. This is similar to packing and unpacking geometry in sops.
No really, workitems can be anything
It's worth emphasising how workitems can be much more than frames.
Everything in tops is a workitem, i.e. a unit of work, a process that is done.
It's intentionally generic nature means it can feel complex compared to Rops, but means it's capable of a lot more. A lot of pipeline tasks, even non vfx tasks can be handled in Tops, because ultimately you're not controlling 3d or geometry, you're controlling processes and tasks.
Generating vs cooking

Generate will make workitems, but do no work. Cooking will actually do the work.
More sops analogies! Watch some of the masterclasses about sops, there's a LOT going on that users aren't aware of. Sidefx folk talk about dirtying sop nodes, traversing bottom up through the graph setting states to understand what nodes need to be cooked, then working top down to do the node cooking. In other words, it first generates a list of work to be done, then it goes and cooks the nodes.
While Sops hides all this from the user, Tops exposes those generate+cook steps to the user, and gives you explicit control to separate them if required.
For simple graphs you don't have to worry about it, Tops will generate and cook automatically. For bigger graphs, you might have some nodes that could take hours to cook, maybe lock up all of a studios renderfarm. It would be hard to create or debug a Tops graph if you had to wait hours on every run!
If you can work with the generate step seperate from the cook step, you might be able to do quite a lot of work designing your graph without ever having to execute any nodes, sort of like keeping Houdini in manual/nocook mode.
To use this you can right click on a node and choose 'generate'. If the node is smart enough, it will generate workitems for you, which you can choose to cook, or just continue to the next node in this high level 'design' mode. When you're ready to both generate and cook a node, you can do this from the r.click menu, or with the keyboard shortcut shift-v.
Inputs and outputs

The previous node output becomes this nodes input. This nodes output changes depending on what the node does!
If tops nodes are to be chained together, they need to pass workitems betweeen them. Similar to Sops and point attributes, Tops workitems have workitem attributes. While Sop points have @ptnum and @P, workitems have an index, input and output defined. Broadly speaking, input is what the node will work on, and output is the finished result of that node.
In the gif above I run have a few nodes chained together. The inputs and outputs are as follows:
- Filepattern - makes workitems from a directory path, eg $HIP/myvideos/*.mp4
- Input - nothing (it doesn't have an input from a previous node)
- Output - a path to an mp4
- Ffmpegextractimages - given a path to a video, create an image sequence.
- Input - a path to an mp4
- Output - an image sequence
You can see these by double clicking on a workitem, the input and output will be listed. Note that if you generate rather than cook, you'll only see inputs (but sometimes you'll see an 'expectedoutput' attribute if the node is clever enough to guess it).
Attributes

Workitem attributes can be directly called in the rest of houdini with the @ prefix.
What if you need to get to those attributes in code? What if you want to define your own attributes? What if you want to use those attributes outside of tops?
The input and output are exposed as @pdg_input and @pdg_output, as well as a few other built-ins. They're listed here in the sidefx docs, but I've made a cheatsheet. Think of these like @ptnum, @P, @N, @v etc:
- @pdg_input - the input to the workitem
- @pdg_output - the cooked result of the workitem
- @pdg_id - the unique id, usually appears like a many digit hash, eg 25325
- @pdg_index - the 'public' index, closer to standard @ptnum 0, 1, 2 etc, but careful, its not guaranteed to be unique!
- @pdg_name - combo of name of the node and the workitem id
- @pdg_frame - the frame if you're doing frame based rendering, 0 if you're not
- @pdg_inputsize - the size of the input (eg if the input is an image sequence, the length of the sequence)
- @pdg_outputsize - the size of the output
These attributes are exposed to the rest of houdini, and are available in parameters wherever you'd use $HIP, $OS, $F, $T etc.
In the gif I use a file pattern top to find *.jpg in a folder. I can then use `@pdg_output` in cops, and the file cop will load the image from the workitem.
Because these are most often used in parameters, the parameter/hscript rules apply; integers and floats usually work directly, strings will usually need to be wrapped in backticks.
Tops vs standard workflows
Tops can break regular Houdini workflows, keep this in mind if you're working with other artists who don't know tops.
Imagine you hadn't read this page, didn't know Tops, and had been given a hip using the tricks so far. Would you be able to understand what's going on?
On top of this, if you have a hip with a tops graph, when you load the hip the Tops graphs is uncooked. That means no workitems exist, meaning anything in the rest of Houdini using workitem attributes will be errored or broken.
Tops is not forgiving to people who don't know Tops. I mean sure, neither is Chops, nor Lops, nor esoteric Dops stuff, but at least with most of those you can save the hip in a working state, and others can load it in that state.
Another source of confusion is the highly parallel and distributed nature of Tops. This gets clearer over time, but again its another thing that can disturb workflow for existing Houdini users, who generaly fear change.
It's not just an instant drop in replacement for Rops, careful now.
Generate mode, automatic vs other
Short version: I mentioned generate vs cook as two seperate steps in Tops, and Tops will usually automatically do the right thing. If you start getting weird results, change the automatic mode ( 'generate when' to 'each upstream item is cooked'), things should start behaving.
Long version:
The ideal tops node should be able to generate workitems without cooking. For example a Mantra Top can look at the frame range parameters, and know you'll need 100 workitems without needing to render.
There's cases where that's not possible. Eg a ffmpeg extract images can't look at the parameters to know how many frames are in the video(s) it will process; it has to actually run ffmpeg, extract the frames, count the result.
In these cases, the 'generate when' parameter tells tops not to try and predict the workitems. Even more accurately, it tells the node that it has to wait for the results of the previous nodes output before it tries to calculate its own workitems.
The chances of miscalculated workitems increases as Tops graphs get more complex. For example a graph might make temp folders, write results in those folders, count the number of files made in those temp folders, and do other things.
The 'count the number of files in the temp folder' node (a filepattern top) in its default state will happily look at a folder path, find the path doesn't exist yet, and generate no workitems. But then when you inspect the finished cooked graph, the folder exists (as now the upstream node to make the directory has cooked), the folder is full of files, and even if you recook the filepattern top now, you'll see it gets results and it all looks fine. Confusing!
Sidefx are trying to fix catch-22 situations like this, but its good to be aware that things like this can happen.
Caching
Short version: If multiple runs of your tops graph look the same, delete results on disk, try again.
Long version:
Because Tops can get right down to that atomic workitem level, it can do some tricks that aren't possible in Rops or other systems. A big part of this is recognising when parts of the network have already been run, and don't need to be recooked.
The example I keep coming back to here of processing a folder of mp4s. Say you had the following chain of tops nodes:
- ffmpeg extract images to convert mp4s into image sequences
- fetch to to run a cops graph that processes those images, renders to a temp location
- fetch to run a geometry rop that traces the images
- fetch to a opengl rop
- fetch to a VAT rop
Obviously a lot of that only needs to run once if you're making minor changes here and there to the network, or if you add a new video, it should only procees that video and skip the rest.
As part of the cook process, wherever possible top nodes will check if output exists where it expects to write files. If it does, it will mark that workitem as complete, skipping a lot of processing time.
Of course this is great when you expect it, infuriating when you don't.
Most nodes have a r.click option after its been cooked, 'delete this nodes results from disk'. For the most part it does the right thing, and it will then of course force a recook of all the workitems on the next run.
If you just want a single workitem recooked, you can go on disk and delete whatever cache that is. I've found there's a r.click menu per workitem dot to get that atomic with your deletes.
Note that sometimes tops gets confused and won't delete files, or will delete too much, best to keen an eye on your files while doing these operations until you get a feel for it.
Caching, be aware of it, make it work for you.
Examples
Simple cache a sim then render locally
 Download hip: pdg_basic_v01.hip
Download hip: pdg_basic_v01.hip
Most existing Houdini users want the basics from PDG; cache a sim to disk, run a render. Maybe chaser mode as a bonus? FFmpeg the result into an mp4, why not eh, YOLO!
Here's that setup. Click the triangle with the orange thingy on it to start. This was one of the first Tops setups I created, I've been told some things aren't ideal, like the map by index (apparently all mapping will gradually be phased out). One day I'll revisit this and clean up.
cache sim is a fetch top that points to a disk cache sop after a simulation. You DON'T want a sim cache running on multiple threads/machines, it should just be one job that runs sequentually. To do this enable 'all frames in one batch'.
map by index controls execution order and limits how jobs are created. If you have node A that generates 10 things, connected to node B that is also set to generate 10 things, PDG's default behavior is to generate 10 B things for each thing made by A. In other words, you'll get 10 x 10 = 100 total tasks. For situations like this, that's definitely not what you want.
The mapbyindex ensures tasks are linked together, so 1 frame of the cache is linked to 1 frame of the render. Further, it allows a 'chaser' mode, in that as soon as frame 1 of the sim cache is done, frame 1 of the mantra render can start, frame 2 of the sim cache is done, frame 2 of the mantra render can start etc.
mantra is another fetch top that points to a mantra rop.
waitforall does as implied, it won't let downstream nodes start until all the upstream nodes are completed. It also subtly adjust the flow of tasks; the previous nodes have 48 dots representing the individual frames, this node has a single rectangle, implying its now treating the frame sequence as a single unit.
ffmpeg top needs some explaining (and some adjustments to the fetch top that calls the mantra rop), which I explain below.
Note that the frameranges on the fetch tops override the ranges set on their target rops by default.
Also note that the button with the orange thingy on it kicks off the output, looking for the matching node with the orange output flag. See in that screenshot how I've left it on the mantra node? That means it'll never run the ffmpeg task. I'm an idiot.
Wedging a rock generator
It was either this or a fence generator, lord knows we need more tutorials on both these important things.
 Here's the hip before getting into tops if you want to follow along:
Here's the hip before getting into tops if you want to follow along:
In this hip is a straightforward rock generator. The sops flow is
- high res sphere
- some scattered points with random scale and N+up
- copy spheres to points
- point vop to displace spheres with worley noise
- attrib noise for more high frequency detail
- attrib noise for colour
- Cd converted to HSV and back again to roughly match the colour of the env background.
So with this all setup, we could randomise a bunch of stuff with tops.
The first thing we'll do is wedge the number of points in the scatter. We'll create a wedge top, which will make a pdg attribute we can reference on the scatter.
- Create a topnet
- Create a wedge top
- Set the wedge count to 5, so we get 5 variations
- Add a new wedge attribute with the multilister
- Attrib name scatternum
- Attrib type Integer
- Set start/end to 2 and 6, so we'll generate a minimum of 2 scatter points, a maximum of 6.
- Shift-v on the node to cook it and see what we have so far.
 Middle clicking on each workitem, we can see that each workitem has a scatternum attribute, starting at 2 and ending at 6. That might be useful for other things, but here we don't want it to be gradually increasing, we want it to be a random integer between 2 and 6. Enable random samples, cook, look again.
Middle clicking on each workitem, we can see that each workitem has a scatternum attribute, starting at 2 and ending at 6. That might be useful for other things, but here we don't want it to be gradually increasing, we want it to be a random integer between 2 and 6. Enable random samples, cook, look again.
 That's better, random samples for each workitem.
That's better, random samples for each workitem.
To use this in the scatter sop, all we do is type @scatternum into the scatter force total count parameter, and bam, its connected.
 Add more entries to the wedge multilister, fill in parameters over in sops, bosh, you have a wedge setup. Note that when you create vectors, you access the components with @attrib.0, @attrib.1, @attrib.2.
Add more entries to the wedge multilister, fill in parameters over in sops, bosh, you have a wedge setup. Note that when you create vectors, you access the components with @attrib.0, @attrib.1, @attrib.2.
Eg here I create a noiseoffset wedge, and drive the point vop noise offset with it.
 So that's all wedging, how do we write this out? We could use a disk cache sop, and set the output name to use @pdg_index, which corresponds to the id of each workitem (ie, 0 to 4 in this case of 5 wedges). Or you could use a rop geometry output top which basically does the same thing.
So that's all wedging, how do we write this out? We could use a disk cache sop, and set the output name to use @pdg_index, which corresponds to the id of each workitem (ie, 0 to 4 in this case of 5 wedges). Or you could use a rop geometry output top which basically does the same thing.
- append a rop geometry output top to the wedge
- set the sop path to the end of your sop chain, /obj/rocks/OUT_ROCK in my case
- set the output file parameter to make a unique file per workitem, eg $HIP/geo/$HIPNAME.$OS.`@pdg_index`.bgeo.sc
- Now if you click through the workitems in the previous node, you can see the file path change if you mmb on the label.
- cook the node, and it'll be baked to disk.
 Here's the finished hip:
Here's the finished hip:
Download hip: tops_rockgen_end.hip
Wedge a sim and generate a fancy QC mp4
 Download hip: top_wedge_sim.hip
Download hip: top_wedge_sim.hip
Ooo, combinations of attributes, captions on the render, an mp4 to comfortably view on the couch, this the houdini dream! And not too hard to setup either.
While the previous example used a single wedge top to do all the randomising, in this case we'll use 2 wedge tops. The first will make 5 workitems, the second will make 5 workitems for each incoming workitem, so 25 in total.
Here's the popnet we'll be working with:
 I've found when setting up top wedging its handy to have the topnet visible in one panel, and the popnet (or whatever) visible in another panel. By using the P hotkey within each pane to toggle the parameters, and making sure each network is pinned, you can alter both networks pretty easily.
I've found when setting up top wedging its handy to have the topnet visible in one panel, and the popnet (or whatever) visible in another panel. By using the P hotkey within each pane to toggle the parameters, and making sure each network is pinned, you can alter both networks pretty easily.
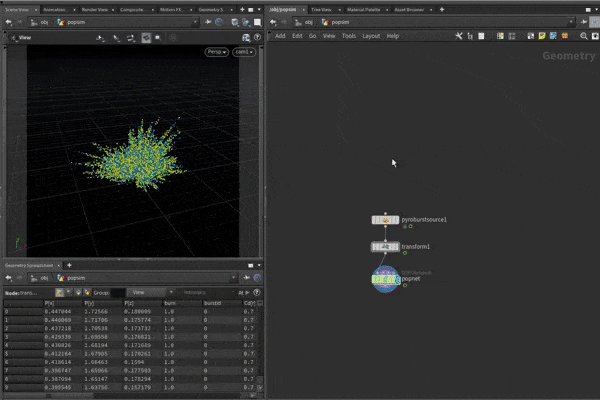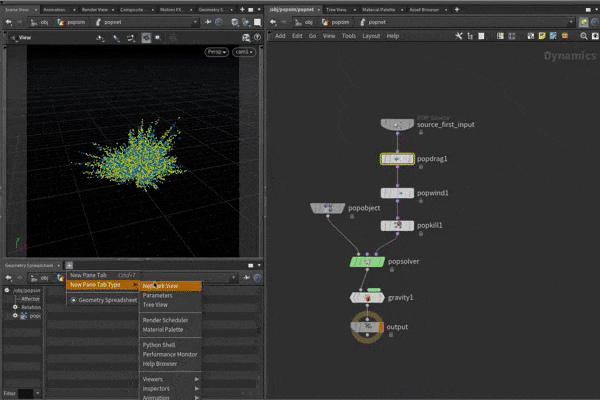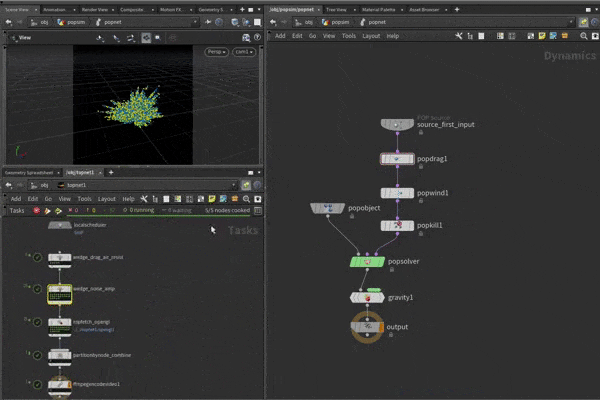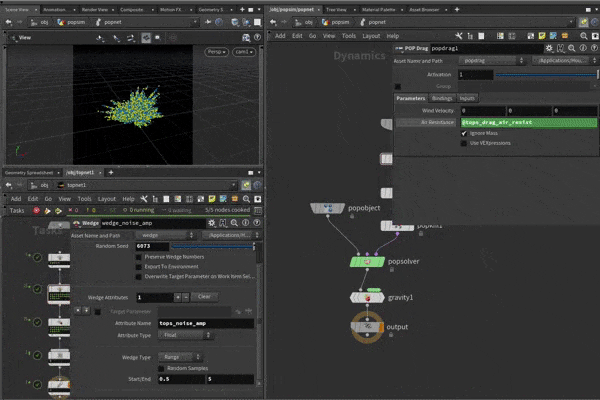 I want to wedge the popdrag air resistance, and the popwind noise amplitude. I make a wedge top, set wedge count to 5, create a tops_drag_air_resist attribute, and type @tops_drag_air_resist into the relevant field in the pop sim.
I want to wedge the popdrag air resistance, and the popwind noise amplitude. I make a wedge top, set wedge count to 5, create a tops_drag_air_resist attribute, and type @tops_drag_air_resist into the relevant field in the pop sim.
I connect another wedge top and repeat the process for tops_noise_amp. Cook the node, you'll see 25 workitems created, if you step through them you'll see each combo of the 2 attributes being set on the sim.
 Now to render this. Move over to rops, create an opengl rop, set the camera. The output files need to be unique per wedge combination, otherwise competing workitems will start overwriting results. A simple way to fix this is to make @pdg_index part of the output filename. Because this is a string parameter, it needs to be wrapped in backticks:
Now to render this. Move over to rops, create an opengl rop, set the camera. The output files need to be unique per wedge combination, otherwise competing workitems will start overwriting results. A simple way to fix this is to make @pdg_index part of the output filename. Because this is a string parameter, it needs to be wrapped in backticks:
 Don't bother setting the framerange, we'll do that from tops.
Don't bother setting the framerange, we'll do that from tops.
In tops append a fetch top, point it at the opengl rop you just made. Set Evaluate Using to 'Frame Range', set the frame range you want and enable 'Cook Frames as Single Work Item'. This means the workitems will end up being an array of the rendered images per wedge combination, rather than generating a workitem for each individual frame.
 Cook now, you'll see renders start, and folders fill up with images. The last step is to make an mp4 out of these image sequences.
Cook now, you'll see renders start, and folders fill up with images. The last step is to make an mp4 out of these image sequences.
Append a partition by node top, cook it. You'll see all the workitem dots are now represented by a single rectangle. If you double click it and browse the output, you can see its an array of all the images from all the workitems:
 That's the perfect array of images to feed to a ffmpegencodeimages top. Do that, cook, hey presto, a mp4 of all the output.
That's the perfect array of images to feed to a ffmpegencodeimages top. Do that, cook, hey presto, a mp4 of all the output.
Buuut.... its just lots of particle variations, there's no way to tell what wedge values correspond to what render. We can fix this by using the comment feature on the opengl rop.
Text overlay with opengl rop
Go back to rops, bring up the parameters for the opengl rop, and in the scene tab go down to viewport comment. This can be used to create a text overlay on the render, so if we use tops attributes here, we can read that in the final renders. R.click on the parameter and choose 'Expression->Edit expression', and combine text and attributes to design a useful overlay:
noise amp: `@tops_noise_amp` air resist: `@tops_drag_air_resist`frame: $F
Except... it won't work. When you hit accept on the editor, it makes the parameter green, assuming its an expression, and the expression isn't valid hscript. Ugh. Luckily hscript is pretty forgiving, all you need to do is wrap the whole thing in double quotes:
"noise amp: `@tops_noise_amp` air resist: `@tops_drag_air_resist`frame: $F"
 Check it! Fancy wedge like the grownups do!
Check it! Fancy wedge like the grownups do!

Mosaic of all the things
 Download hip: top_wedge_sim_mosaic.hip
Download hip: top_wedge_sim_mosaic.hip
Mosaic, or contact sheet, or montage as its strangely called within Imagemagick, the ultimate way for a time pressed fx lead to review their teams work and say 'I hate it all, start again'.
That I could do this without reading the docs surprised me, taking that as further proof that I'm starting to understand Tops.
The Imagemagick node lets you do image processing. One of its tricks is a mosaic effect, which they call 'montage'. If you give it an image sequence of frames 1 to 10, you'll get those 10 frames laid out together in a grid.
That's almost what we need here, but rather than giving it frames 1 to 10 and lay them out in a grid, we'll grab all the first frames from the wedges, put those in a grid, save that image to disk.. Then all the second frames from all the wedges, lay those out in a grid, save that image to disk... one we have all the grids, make a mp4 out of those grids.
This is a roundabout solution, but basically its expand the wedges out to be individual frames, collect together the matching frames, montage them, ffmpeg them.
- copy @pdg_index to a new attribute, @wedgeindex
- workitemexpand top so that we go from 25 items of 50 frames, to 1250 individual frames as workitems
- the frame number isn't stored per workitem, so create a frame attribute by parsing the file path on each workitem
- partitionbyattribute using @frame, and on distinct attribute values. This partitions all the frame 1 images together, all the frame 2 images etc
- The results come back slightly out of order, but on the advanced tab, we can tell the partition top to sort by the @wedgeindex we created in step 1
- Imagemagick top, montage mode, this makes a mosaic from each partition. Because we have all the frame 1's in a partition, they all get assembled into an image, as do frame 2, frame 3, frame 4...
- waitforall (or partitionbynode), basically just get it to make a single array of all the images so that we can...
- ffmpegencodevideo to make an mp4
Tops and sims further work
Looking at the result of the last 2 examples, there's a few things to note:
Nice names help discoverability
When you use tops attributes in parameters in the rest of Houdini, they end up looking just like regular attributes. I don't like this.
In my world, I'd want nodes to have a tops badge so I can easily see its being controlled by tops. The attributes themselves wouldn't re-use the @ prefix ( # maybe? Or ~, ie a tilde for tops? Or t@foo instead of @foo ?), and expressions would go a different colour when driven by tops attributes.
Until Sidefx see reason, you can help yourself and others by naming your attributes nicely. Don't use @noiseamp, use @tops_noiseamp. See? Now it's clear it's from tops!
Fetch top Frame by frame vs complete sequence
If you run a regular sim through a regular rop without caching the sim first, Houdini will sim each frame as required, then render. If you send that rop to a render farm, and the farm splits the job into one frame per render blade, then each blade will have to sim from frame 1 to the frame it needs to render. Not very efficient.
The better option would be to cache the sim first, then have each blade render the cache. Tops is no different. If this were a heavy sim, I would put a disk cache sop after the popnet, use a fetch top to execute it (making sure the cache had a wedge index so they don't overwrite each other!), and then I could run the opengl fetch top in whatever mode I want.
Workitems as frames vs workitems as image sequences, general efficiency
Related to the above, if I were rendering from a cache instead, then I could have the workitems render individual frames rather than the entire sequence. But think about this; each workitem is having to spin up its own instance of houdini, the opengl rop, render, then shut itself down again. For a simple render like this, it's probably doing more work just to startup and shutdown than to actually render. It's probably more efficient to startup, do the sequence, then shutdown. At a big scale this would also be impacted by licences; each tops graph in a render farm would consume a license per blade, you'd quickly eat up all your licences in a churn of blades starting and shutting.
Workitems as arrays elegance vs workitem busy work later on
This setup looks neat early on with with the fetch, partition, ffmpeg top to make a sequenece of renders, but gets ugly when making the mosaic as I have to do lots of work to make attribs, expand, partition, sort.
Alternatively I could have run the fetch to make a workitem for every frame (if I cached the sim first), which would mean I could directly partition the results by frame. Neater, but now potentially less efficient.
I don't know if one way is more elegant than the other (and I'm assuming there's probably a better way to make the partitions), but it's something to keep in mind.
Debug workflow with cached results, generate vs cook
I'm getting better at predicting when tops needs to do work, and when I can take shortcuts. I know that once the fetch top has run the opengl rop, any of the downstream nodes that are just manipulating workitems and attributes are basically instant. It's only when nodes have to do work (ie the ffmpeg and the imagemagick nodes) that I'd get a processing time hit.
Hence a lot of the debugging was appending nodes after the opengl fetch top, cook, inspect a result, frown, try another node, cook, inspect, grin, append a new node, cook that, tweak it, recook, inspect, etc. Tops is more efficient to work with for debugging workflows than I first gave it credit for.
Specifically for the debugging, the actual workflow is to say append a node, cook it, double click a workitem dot, look at the output. If its an array of frames, expand that to see if its doing what I expect. Eg for the mosaic workflow I could see it was collating all the frame 1s, frame 2s etc together in the partition sop, but the results weren't sorted:

All the frame 1s together, but the order is random
That's how I knew I had to store the workitem index so I could sort it properly later. It's not quite as fluid as using the geometry spreadsheet in sops, but it's not bad.
Even when hitting the heavy 'do work' nodes, tops will often aggressively lean on the cached results on disk, and rarely do work if it doesn't need to. I'm trusting it more and more to do the right thing, and generally know it'll only start doing heavy lifting if I right click on a node and select 'delete results on disk'.
Use the overlay text top

Drop shadows? Font choice? Damnit.
After working out that comment trick and feeling smug, I stumbled across another top, Overlay Text.
It's a HDA that gives you a nice big text editor in its parameter interface, and under the hood uses a cops graph to generate text and overlay it onto the incoming workitems (which would be images from a render). This means you can have much more control over size, layout, font etc than the opengl comment top, and it'll work over any render. Oh well. Still pleased with my trick.
Calling an external app (avconvert) with the generic generator
 Download hip: tops_avconvert_generic.hip
Download hip: tops_avconvert_generic.hip
FFmpeg is great, but there's some Apple specific stuff that it can't do. The always amazing Ben Skinner pointed out that there's command line tools that ship with OSX to do Apple specific video stuff, was curious how to call them from Tops.
This page gave the clues, with a command line string we could port over to Tops:
https://kitcross.net/hevc-web-video-alpha-channel/
The generic generator is the top to use here. It provides a command line parameter, all you do is fill in the bits, and use the attribute and backtick stuff to construct the bits that will change per workitem.
So if the example command line string is
avconvert --preset PresetHEVC1920x1080WithAlpha --source source.mov --output output.m4v
The first the we need to do is swap source.mov for @pdg_input. Remember, this is a string parameter, so we need backticks to ensure it gets evaluated as an expression:
avconvert --preset PresetHEVC1920x1080WithAlpha --source "`@pdg_input`" --output output.m4v
Next is the output.m4v. We want to make sure each workitem writes to its own unique name. Cos I'm using a filepattern top right at the top of the flow, it generates @filename for me, so I can use that to create the name. Again, watch those backticks:
avconvert --preset PresetHEVC1920x1080WithAlpha --source "`@pdg_input`" --replace --output "$HIP/videos/`@filename`.m4v"
This will work, but for bonus points we can also fill out the 'expected outputs' tab. Set expected outputs to 'file list', and the output file parameter matches the end of the command string:
"$HIP/videos/`@filename`.m4v"
Why do this? Well, this means that if we just use generate instead of generate+cook, the workitems will have a @expectedoutput attribute, so we can build up the rest of the network, do testing, without needing to run this cook every time.
Partition files by suffix, convert between partitions and workitem arrays
Download hip: tops_partition_to_workitem_arrays.hip
I can use a filepattern top to search through $HFS/houdini/pic/* and generate 112 workitems, which are a mix of .pic, .png, .rat, other formats.
To group these by filetype, I can disable 'Extension in Filename Attribute' on that top, and append a 'Partition by attibute'. Set Partition By to 'Distinct Attribute Values', add an attribute to the multiparm, set name to extension.
Cook, and you'll see there's partitions based on the extension.
 Fine, but what if you need workitems arrays, like you get from the ffmpeg extract images top? For example I had a process where I started with those results, split some workitems off, did things, and wanted to merge with the original stream, but now I had a mix of partitions and workitems.
Fine, but what if you need workitems arrays, like you get from the ffmpeg extract images top? For example I had a process where I started with those results, split some workitems off, did things, and wanted to merge with the original stream, but now I had a mix of partitions and workitems.
A handy trick is to use a generic generator to filter the results. Append one, enable 'copy inputs to outputs' and cook, now those partitions have been translated into workitems with arrays.

Export RBD fracture pieces to seperate fbx files
 Download hip: tops_fracture_fbx_export.hip
Download hip: tops_fracture_fbx_export.hip
Simple one, but the more practical examples that show up on this page the better!
Someone from the games scene had run geo through an RBD fracture sop, and asked how they'd export each piece into individual fbx files.
I figured it'd be handy to write down my though process to build this hip, as I'm finding I can get solutions in tops going pretty intuitively now.
- Made a pig, rbd fractured it.
- Looked in the geo spreadsheet to see what attribute I can use to identify each piece, it's @name.
- Made a new topnet, figured the node I want would have 'geom' in the title. Looked, found geometryimport.
- Browsed through the parameters, 'data extraction' tab looked like a good place to start.
- Set 'copy from class' to primitive
- Set 'piece attribute' to 'name'
- Now had to find where to get the geo from. Back to the 'source' tab, change 'geometry source' to 'sop node'
- Set sop path to my pig
- Tops likes to work with stuff on disk a lot, but I didn't need this here, as I figured I'd be doing the work in sops, and just driving it with tops attributes. As such, 'storage' tab, set 'store geometry as' to 'geometry attribute'.
- Hit shift v, see workitems populate. Can middle click on them and see tops has create an attribute piecevalue that contains the name of each fracture piece.
- Head back to sops
- Append a split, set the group to @name=`@piecevalue`
- Display it, jump back to tops quickly, left click a few workitems, can see the pieces are being isolated properly.
- Append a rop fbx output, set output file to $HIP/fbx_fracture/`@piecevalue`.fbx
- Jump back to tops, create a rop fetch to run this rop for us. Set rop path to /obj/mygeo/rop_fbx1
- Shift-v to run the graph, see it start to save to disk.
- It's slow though. As explained elsewhere here, each workitem is starting a seperate hython under the hood, we're paying the houdini startup time for every workitem. I'm impatient, lets use services to speed this up. Stop tops running with the X button at the top of the network view.
- Click 'Task' just to the right of the cancel button to bring up the tops menu, jump down to PDG Services
- Click the big start button to create a worker pool, wait until the tiny yellow light turns yellow-green (its hard to see, annoyingly small)
- On the ropfetch, jump to the Service tab enable Use Rop Fetch Service
- shift-v the graph again, after a little pause as tops gets itself ready, the workitems should process MUCH faster.
Incedentally, you might be curious why I designed the network this way, with tops 'remote controlling' stuff over in sops, vs doing a purely natve thing in tops. The answer is ¯\(ツ)/¯ .
Well actually the answer is more what works for you. I'd say this is how a lot of my tops setups start, a thing I've built in sops which I then want tops to orchestrate. Other times I'll start a project knowing its a tops thing, and I'll use the native tops nodes to do the stuff. Where I have foresight and planning I'll try and do the latter approach, but knowing how little foresight and planning I have in my brain, I often end up with the former.
Tips
Services
When you get into tops, you start to notice the delay it takes for workitems to start processing. Often the spinup time can be longer than the actual workitem processing time.
TLDR: Too lazy to read? I made a quick video runthrough for a sidefx forum post, you can watch it here: https://www.youtube.com/watch?v=I7GPZxygUys
I mentioned at the start that Tops is essentially controlling lots of batch mode houdini's for you, called hython (houdini python, get it?). Each workitem has to start hython, which takes about the same time to start as you running Houdini in regular UI mode. If you have lots of plugins, renderers, pipeline code etc, and your desktop Houdini takes 30 to 60 seconds to start, so will hython, and hence you'll get a 30 to 60 second delay for each of your workitem cooks.
A way around this is with Services. Tops can start multiple hythons in a worker pool, and they will remain active until you close Houdini. When workitems need to be cooked, Tops communicates directly with those already warmed up hython workers, so startup time is reduced from 30 seconds to half a second.
To make this work, you need to start Tops services, which you do from the Tasks menu, towards the bottom:
 Then from this rather janky looking interface, click start. It'll take a few seconds, but eventually the status light will turn green to show you the pool is activated and ready. Here I'm configured for a pool of 6 workers. You can close this window when the light is green.
Then from this rather janky looking interface, click start. It'll take a few seconds, but eventually the status light will turn green to show you the pool is activated and ready. Here I'm configured for a pool of 6 workers. You can close this window when the light is green.
 The last and slightly annoying step is that Top nodes need to opt-in to use services. On Top nodes which support this, there'll be a services tab, and in that will be a checkbox you need to enable:
The last and slightly annoying step is that Top nodes need to opt-in to use services. On Top nodes which support this, there'll be a services tab, and in that will be a checkbox you need to enable:
 Not all Top nodes support this, generally speaking those that don't won't benefit from services anyway (things like modifying attributes on workitems, filepattern tops nodes to scan directories etc).
Not all Top nodes support this, generally speaking those that don't won't benefit from services anyway (things like modifying attributes on workitems, filepattern tops nodes to scan directories etc).
The first time you run with services, you probably won't notice a speed boost. Every subsequent run will be much faster. Definitely worth playing with!
In Process
Services are neat, but what if you're running something really fast, it's only a couple of workitems, even the time taken to spin up services is more time than you can be bothered with? Hell, you might notice that you can manually click through the workitems in the GUI and see the results instantly, can't we just do that?
Yes you can. A newish tops option is to go 'in-process'. Rather than use external hythons to run your stuff, it just uses your current houdini gui to do the work. This obviously has some caveats:
- Your Houdini session will get locked up while its cooking, no backgrounding here
- It can only do one work item at a time, so no parallel execution
- Not all tops nodes are compatible with the in-process mode.
If that all sounds like a reasonable compromise, use the tab menu to create an in-process scheduler, go to the controls on your topnet and set the default scheduler to this new in-process one, and have a play.
Often when I'm just starting to sketch out a tops graph, I'll use the in-process mode to get fast feedback, then swap over to services as the network gets heavier.
Tops vs PDG?
They're essentially the same thing. PDG stands for Procedural Dependency Graph. You could get really pedantic and say that TOPs, or Task Operators, are the nodes within the Procedural Dependency graph.
You might also call Sops a PGG (Procedural Geometry Graph) and Cops a PCG (Procedural Compositing Graph).
BUT YOU DON'T. YOU CALL THEM SOPS AND COPS.
I think using PDG as a name is needlessly confusing (especially with the builtin @pdg_ prefix on attributes), so I'm trying to say Tops whenever I can.
Where's the Tasks menu?
The help mentions some stuff in the 'Tasks' menu, I couldn't see it.
Well, it's there. Hidden in plain sight. Lets play 'Which of these things is a menu, but doesn't look like a menu':

What do the colours mean in the mmb info for workitems?
Colours represent the attribute types. Note that there's no distinction for arrays (see the float array in with the other floats)
- dark cyan - internal attributes
- pink - string
- green - integer
- yellow - float
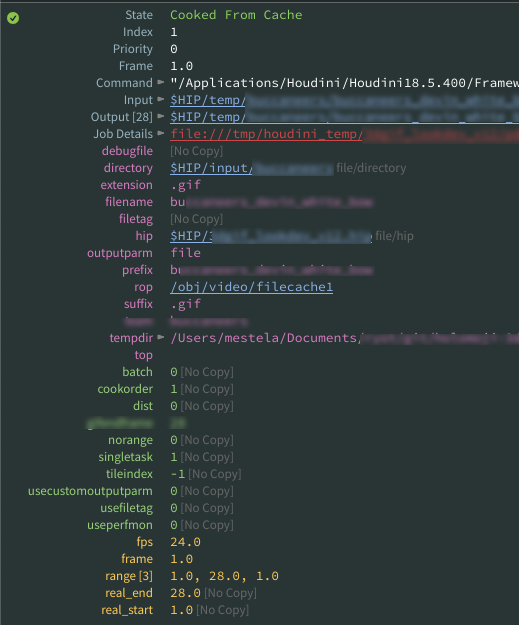
When pdg_input and pdg_output are blank

A generic processor top wll not generate an output attribute unless you tell it to.
In summary, check the nodes above the erroring one, especially if they have an unchecked copy inputs to outputs toggle.
I've had a few occasions where I'll have a node error, go inspect a workitem and see that @pdg_input or @pdg_output is missing or empty. The culprit is always an upstream node. Related to what I mentioned before, nodes usually expect an input, and most of the times set an output.
This isn't mandatory though! If you insert nodes into an existing network, those node might not get the input nor set the output, always check their middle click info panel to see what going on.
For example:
- Wedge tops if appened to a filepattern top will have inputs and outputs, but wedge nodes by themselves don't, even if chained together.
- Generic processor tops won't generate output by default, unless you enable 'copy inputs to outputs'.
In bigger networks copy pdg_input to something else
You've seen by now that each node reads pdg_input from the previous node, and may or may not alter it to send to the next node. This is fine for smaller clean networks, but when you introduce branches, or insert lots of nodes in the middle of a network, nodes downstream might break because their expected pdg_input has changed.
It's a good habit to use an attribute create to name thing explicitly. Eg, you use a filepattern top to grab a bunch of alembic .abc files. Immediately put down a attribute create, name the attribute 'tops_abcpath', and the value will be `@pdg_input`. Any nodes from this point on can refer to @tops_abcpath, and you'll be confident its unlikely to change.
The analogy here is using @Cd in sops to drive masks/geometry deletion/pops emission. Fine for small things, but as complexity grows, you're better off using explicitly named attributes to avoid confusion or unintended behaviour later.
Set a limit on the number of workitems
 Say you have a folder full of images that you want to process, but for testing just want the first 5 images.
Say you have a folder full of images that you want to process, but for testing just want the first 5 images.
A filterbyrange top will let you do this.
Pick 2 items from each group of workitems

Get the first 2 videos from each subfolder. Remember to turn on 'items in upstream partition'!
I have a filepattern searching an inputs folder. That folder is full of subfolders, say animal names, and in each of those are mp4's I want to process. So the folder structure might look like this:
 Now say while testing I only want to grab 1 or 2 from each category?
Now say while testing I only want to grab 1 or 2 from each category?
A partition top lets you collate workitems, similar to packing geometry. You can partition in many ways, here I'd use a partition by attribute top. I'd use an attrib from string top to split off the animal type into its own attribute, @animal, then partition by 'animal'. Make sure 'partition attributes independently' is set.
Now we can unpack them again using a work item expand, but handily this has several ways to do that unpack. In this case 'first N', sounds right, so we can expand only the first 2 from each animal.
On this node, make sure apply expansion to: is set to 'items in upstream partition', otherwise it can do odd things like duplicate the first item it finds per animal twice. Remember @pdg_index isn't guaranteed to be unique in the way @ptnum is, so when relying on tools to sort by index, it can easily grab stuff you don't expect.
Finally to make sure the output is sorted per animal, a sort top can be used, with the name parameter set to 'animal'.
Make workitems from a string array

The alt title for this section is 'make a bunch of fake animal mp4s from some text cos I'm too lazy to make them manually'.
Download hip: tops_animals.hip
Read this, but also read the next section for an even easier method...
The previous example used to have some quoted text where the screenshot of the files go, like this:
/inputs/dog/poodle.mp4/inputs/dog/pug.mp4/inputs/dog/terrier.mp4/inputs/dog/labrador.mp4/inputs/cat/black.mp4/inputs/cat/striped.mp4/inputs/cat/white.mp4/inputs/cat/ginger.mp4/inputs/cat/longhair.mp4/inputs/bird/parrot.mp4/inputs/bird/gull.mp4
I thought a screenshot of files+folders would look better, but how to make fake mp4s with all those locations quickly? That itch to eat my own dogfood was strong, so I figured there must be a tops way. Here's how:
- Attribute Create, name 'test', paste in the text, which appears with newline symbols ( ¶ ) and spaces.
- Attribute From String to split @test into an array using a space as the delimeter. This creates a new attribute @split, which is a string aray of the filepaths.
- Work Item Expand, expanding on 'upstream attribute', and the attribute is 'split'. Now I have 12 workitems, each has @expandvalue set, which is the name of the fake mp4.
- Text Output, set the path to $HIP/animals/`@expandvalue`, cook it, hey presto, files on disk!
Note that the first workitem errors. The first split element is an empty string, so the Text Output node complains that it can't create that file. I could limit by range and remove the first workitem, or use a rule or something to remove it, but I have my fake mp4s now, no need. 😃
Version 2
An even easier method!
Download hip: tops_animals_v02.hip
I noticed that Attribute From String has another option for 'Store Result as', which is 'Seperate Work Items'. Perfect, can skip the Work Item expand, and just change the Text Output path to use @split rather than @expandvalue.
workitem @pdg_index isn't unique like @ptnum
For a while I was treating the workitem @pdg_index like @ptnum, in that I assumed it was always unique, would resort and reindex as you add and remove workitems.
I've since found that's not the case. If you do things like merge different streams, or do partitioning and unpacking, you could have 5 workitems that all have a @pdg_index of 0. That means if you do things like say limit by range to 0, thinking you'll just get the single zeroth entry, you'll get back 5.
A bit confusing, you have to use things like sort tops and other nodes to force workitems to reindex, I'm still working out the best method for this.
Get framecount from ffmpeg extract images
The ffmpeg extract images node usually generates a output attribute which is an array of the images its created. At some point this stopped working for me, so I had to find another way to count the images.
After talking to support it was due to putting quotes around the output parameter path. Doh. Still, leaving this here as it's still a good mini example of tops workflows.
So as I said, we could try and find the files in the ffmpeg output folder for the node. A filePattern top can do this. If the ffmpegextractimages node is using the default
$HIP/images/`@pdg_name`/frame%06d.jpg
The following filepattern node should point to the folder above it, ie
$HIP/images/`@pdg_name`/*
It also has 'split files into seperate items' turned OFF, so that way I just have a single workitem per image sequence.
If you try this now, it won't generate any workitems. The default generate mode will mean it tries to look in that folder straight away, finds no images, and as such returns no workitems. Change the generate mode to 'each upstream item is cooked', then it works as expected.
Ok great, but where's the actual number of frames? It's there, annoyingly hidden. There's some tops attributes that don't appear in the middle click info, one of those is @pdg_outputsize. In this case, unsurprisingly, it returns the amount of frames in the sequence. So with an attribute create node, you can create a new integer variable called framecount, and set an expression to use @pdg_outputsize.
 Note that you don't need to change the generate mode on the attribute create. As soon as any upstream node is set to be dynamic (ie, it has to wait for previous items to cook), all subsequent nodes are also made dynamic.
Note that you don't need to change the generate mode on the attribute create. As soon as any upstream node is set to be dynamic (ie, it has to wait for previous items to cook), all subsequent nodes are also made dynamic.
Create attribute from string array element
Related to the previous example, I used an attribute from string node to split a directory path into components, and then wanted to create a new attribute based on the last part of that path. Annoyingly I couldn't work out how to get an array element from the standard attribute create node, so I gave up and used a python script node instead:
python
renderpass = work_item.attrib('split')[-1]
work_item.setStringAttrib("renderpass", renderpass)renderpass = work_item.attrib('split')[-1]
work_item.setStringAttrib("renderpass", renderpass)TIME PASSES
Had another go, here's a purely node based approach:
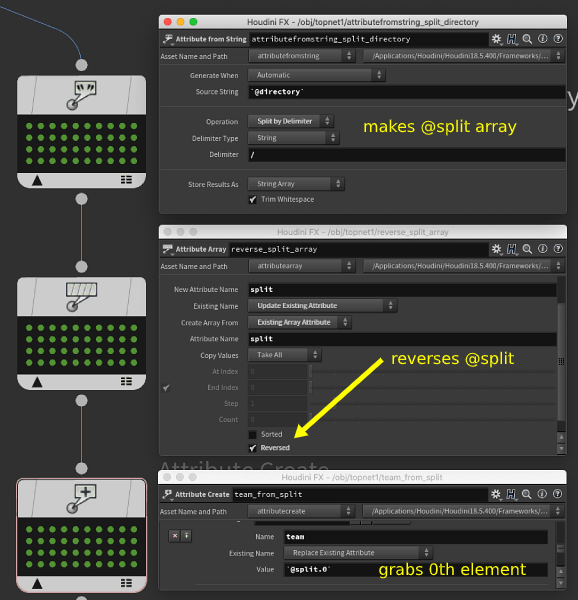 Tops array attributes can be accessed with @attrib.0, @attrib.1, @attrib.2 etc, but there's no python style @attrib.-1 to get elements from the end of the list. As a workaround we can simply reverse the array. So:
Tops array attributes can be accessed with @attrib.0, @attrib.1, @attrib.2 etc, but there's no python style @attrib.-1 to get elements from the end of the list. As a workaround we can simply reverse the array. So:
- attribute from string top, split by delimiter enabled, '/' as the delimeter. A @split attribute has been created, an array of the file path components.
- attribute array top, update existing 'split' attribute, reversed enabled
- attribute create top, uses `@split.0`
Rename files
Be careful! The rename top works, but its very easy to destroy a bunch of files, delete them without a trace, so tread carefully.
I had a bunch of files with spaces in names, hyphens, brackets, all sorts of bad stuff. I wanted them to be cleaned up to only use letters, numbers, underscores.
A python script top can use regex to generate cleaned names:
python
import re
oldname = '`@filename`'
newname = re.sub("[^0-9a-zA-Z]+", "_", oldname)
newpath = '`@directory`'+'/'+newname+'`@extension`'
work_item.setStringAttrib('newpath',newpath) import re
oldname = '`@filename`'
newname = re.sub("[^0-9a-zA-Z]+", "_", oldname)
newpath = '`@directory`'+'/'+newname+'`@extension`'
work_item.setStringAttrib('newpath',newpath)You can then feed this to a rename top (make sure to enable 'copy inputs to outputs' on the python script top):
 But like I said, be careful. It seems to run immediately, even in generate mode, so if you don't have your attributes right, it will happily rename everything to a null name, effectively deleting it.
But like I said, be careful. It seems to run immediately, even in generate mode, so if you don't have your attributes right, it will happily rename everything to a null name, effectively deleting it.
Attribute from string expressions
Simple pattern
This is a remarkably powerful node to let you split simple strings easily, and complex strings with powerful (but frustrating) regex hell.
Simple strings are nice and efficient. Say you have a bunch of files you pull in with a filepattern top that look like
beauty_indirect_v03.0035.exr
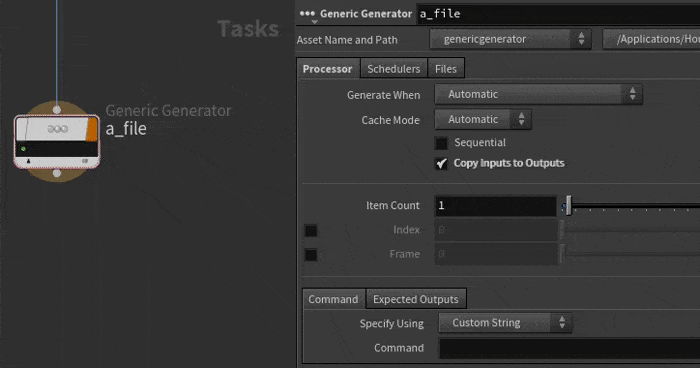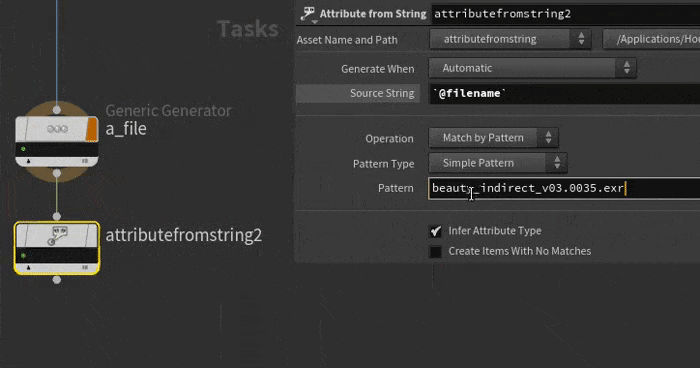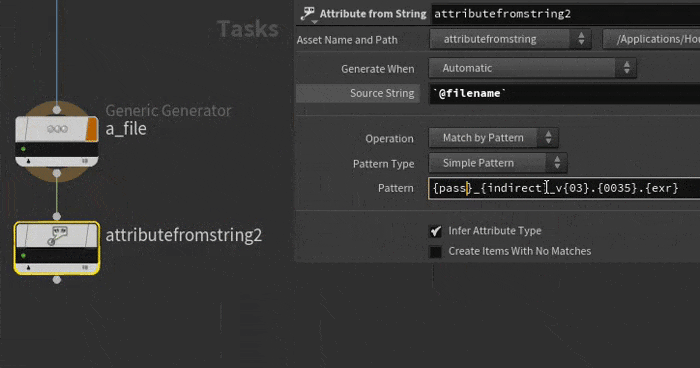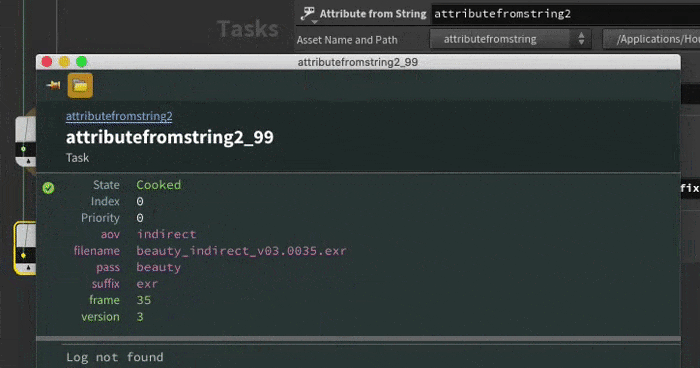
And you want to create nice attributes out of those various bits. Append a attribute from string, set the string to `@filename`. To do the pattern matching, it's easiest to explain it in 2 steps:
First, copy one of the filenames into the pattern parameter and wrap the bits of the file you want in curly brackets. Skip the bits you don't need, like the '_v' before the actual interesting version number:
{beauty}_{indirect}_v{03}.{0035}.{exr}
Now change the stuff in the curly braces to the attribute names you want:
{pass}_{aov}_v{version}.{frame}.{suffix}
Cook the top, hey presto, its tokenized the string and made attributes for you. It even change the string '0035' into a float attribute of 35, pretty clever. Easier to see in a gif probably:
Regular expression
Hoo boy. The help just gives a link to the official python regex docs, but thats it. Took a few goes to understand how to use it.
Make sure to bookmark this, keep it handy when trying to construct regex (thanks Jake Rice for the link!) : https://regexr.com/
In this case I'm using a filepattern top to grab butterfly* from $HFS/houdini/pic/butterfly*. The files look like this:
butterfly1.picbutterfly2.picbutterfly3.picbutterfly4.picbutterfly5.picbutterfly5Bump.picbutterfly6.picbutterfly7.pic
Notice that there's no separator between 'butterfly' and the number, and that one 'Bump' image in there too? This is more than the simple pattern mode can handle.
Enter regular expressions. Here's the pattern I used:
(\w+)(\d+)(\w*)
 What does that mean? Similar to the simple pattern, regular brackets identify groups, they'll just be numbered rather than named. The actual tokens themselves:
What does that mean? Similar to the simple pattern, regular brackets identify groups, they'll just be numbered rather than named. The actual tokens themselves:
- \w+ - find one or more letters
- \d+ - fine one or more digits
- \w* - find 0 or more letters
Simple right? No, not really, but powerful. Regular expressions can do a lot more, you can name your groups, do conditional logic, all kinds of text processing tricks. Just keep in mind the classic quote from Jamie Zawinski about regular expressions:
Some people, when confronted with a problem, think "I know, I'll use regular expressions." Now they have two problems.
Regular expression and named outputs
Oh you don't like the index notation? You wanna go all the way and confuse your peers? Ok then.
Put ?P<groupname> at the start of the regex code. So to convert the previous example to create attributes called @prefix, @digits, @suffix:
(?P``<prefix>\w+)(?P``<digits>\d+)(?P``<suffix>\w*)
Ugh.

Update attributes based on value without code
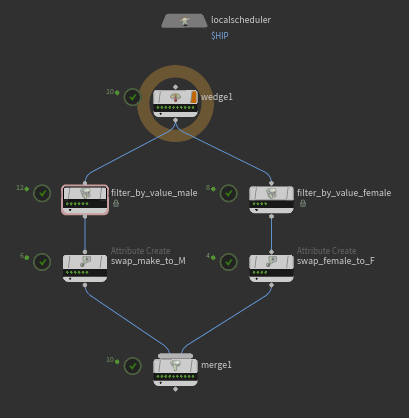 Download hip: tops_attrib_male_female_to_M_F.hip
Download hip: tops_attrib_male_female_to_M_F.hip
Requires sidefx labs to be installed (its now an option right on the installer, SUPER handy, just do it!). They're doing their best to reduce the need to know python to use Tops. Right now its almost unavoidable, but its a noble goal.
Use the labs 'filter by value' to split male from female, then attrib create to swap the value from 'male' to 'M' and 'female' to 'F', then merge.
String expressions and finding text
I struggle with this every time, writing this down to save future Matt.
The short answer is 'use labs filter by value', it's designed to help avoid the fiddly nature of string manipulation in tops expressions. But lets peek under the hood.
I have a bunch of workitems with a @directory attribute, and I want to split out those that have 'disp' in that attribute.
The Filter by Expression top, or the Split top are the vanilla nodes to use, but the format of the expression isn't intuitive.
Hscript makes it easy to compare numbers with < > =, but what about strings? You'd think after x years of using Houdini I'd know it automatically, but no. The answer is strmatch(). Don't forget to include wildcards (I always forget), and because the expression parameter expects an integer (basically 1 is true, 0 is false), you don't need backticks:
strmatch('*disp*',@directory)
That's a short-form. If you want to be pedantic (you're using Houdini, of course you do) strmatch() will return 0 if it can't find a match, 1 if it can, you should do a proper comparison test:
strmatch('*disp*',@directory)=1
strmatch matches on exact case. If you want to match 'disp' and 'DISP', use the confusingly named strcasematch():
strcasematch('*disp*',@directory)=1
You could also use strcmp, but that returns 0 for an exact match, 1 or -1 for other matches, which is confusing. You can invert that with an exclamation mark, but its harder to read:
!strcmp(@extention, '.zip')
What about python? See the python section further down. I try to keep tops all python, but this tests my patience with how wordy it gets.
Ffmpeg and non sidefx rops
I had a few issues getting ffmpeg to make mp4's from a renderman rop. In the end the fixes were relatively straightfoward.
 The ffmpeg top needs to know a few things:
The ffmpeg top needs to know a few things:
- what part of the upstream nodes are making images, set with output file tag
- what the location of those images are, set with output parm name
- that the images are bundled into a single unit of work, using a waitforall top.
Top nodes can tag their output(s), in this case the ffmpeg top expects the images to have a 'file/image' tag. On the fetch top for renderman rop enable 'output file tag' and use the dropdown to select 'file/image'
To know what file name to put in that tag, enable 'output parm name' and set it to 'ri_display_0'. This is the parameter on the ris rop where the image path is set.
To bundle all the frames into a single unit, use a waitforall top.
A last specific thing for our setup, our build of ffmpeg didn't understand the '-apply_trc' option, so I disabled it.
Tops and imagemagick to make gifs via generic processor
 Download hip: tops_imagmagick.hip
Download hip: tops_imagmagick.hip
If you try the gif imagmagick tricks on the General page with tops, you'll find nothing works. In the current build (18.5.633 in Oct 2021) you don't get enough control over the command string. It needs the options and the images in a specific order, tops won't let you.
Instead you can use a generic processor top to just call your completely custom command, which I used earlier to run the OSX native video conversion tool.
I tried dropping this command into the node, expecting the waitforall above it to send the correct images to imagemagick:
magick convert -loop 0 -delay 2 "`@pdg_input`" -layers OptimizeTransparency +map $HIP/out.gif
But it no worky. If you look at the log, you can see that @pdg_input just gets expanded to the first image, rather than the full sequence. Boo. JeffLMnt had the fix though; the pdginputvals command will expand that tops attribute into a full string, with each value separated by a space, and surrounded in double quotes. Handy! So this'll work:
magick convert -loop 0 -delay 2 `pdginputvals("",0)` -layers OptimizeTransparency +map $HIP/out.gif
But it's probably tidier to create attributes in a previous node, then have this command use cleaner attribs. Here's what my attribcreate looks like before the generic processor:
And the line now becomes this:
magick convert -loop 0 -delay 2 `@images` -layers OptimizeTransparency +map `@output`
As a bonus, you can put @output into the second tab to define the expected outputs. This will mean you can r.click on the node and choose 'delete outputs from disk', and it'll do what you want. Neat.
Combine tops workitems in sops and lops
 Download hip: tops_combine_workitems.hip
Download hip: tops_combine_workitems.hip
As always, credit to Ben Skinner for this, and also to Michael Buckley at SideFX for further pointers.
If you've read this far you should have a good mental model of tops; workitem streams run in parallel independant lines, you can 'pack' them into partitions, great.
But what if you want to collect all your workitems together and do stuff to them in other Houdini modules? pdg_input is always per workitem, and partitions are more like a container than something you work with directly.
There's a few methods, but this technique suggested by Mr. Buckley and Mr. Skinner is working well for us.
First we need a way to collect the attribute we want from all workitems within a partition. When you create a partition with the waitforall top, you can also ask it to do operations on the attributes, similar to an attribute promote sop. One of these options is to create an array out of the workitem attribute.
In the example hip each workitem has an attribute 'image_path', the partition converts this into a string array:
 Now that we have a single array, we can use a for loop in either sops or lops to process it. Lets look at each in turn.
Now that we have a single array, we can use a for loop in either sops or lops to process it. Lets look at each in turn.
Using the tops array in Sops
Here I decided that I'd create a point per workitem, with image_path stored as an attribute. I used a detail wrangle to do this, and used the hscript expression pdgattribvals. This will expand the tops attribute into a single string, with each value separated by spaces. Hacky, but works a treat. I can then split on the spaces, and in a vex for loop create the points with the attributes I want:
vex
string tops = "`pdgattribvals('image_path')`";
string paths[] = split(tops,' ');
foreach (string p; paths) {
int pt = addpoint(0,0);
setpointattrib(0,'image',pt,p);
}string tops = "`pdgattribvals('image_path')`";
string paths[] = split(tops,' ');
foreach (string p; paths) {
int pt = addpoint(0,0);
setpointattrib(0,'image',pt,p);
}Sweet:
 Now we can use a sops for loop in points mode to do work, here I use this to make a little gallery of traced images.
Now we can use a sops for loop in points mode to do work, here I use this to make a little gallery of traced images.

Using the tops array in Lops
Interestingly using this array in Lops is easier. Lops loops can work with strings, and will automatically split on spaces. It's like its been pre-designed to work with pdg_attribvals!
 This gallery was more about cards mapped with images, so I need a unique card per workItem, as well as a unique material per workitem. The for loop in Lops exposes more psedudo attributes, @ITERATION and @ITERATIONVALUE, these can be used to ensure everything is split out properly and named correctly. A sopcreate is used to make the card, using `@ITERATIONVALUE` on a trace sop to generate the geo with a bound, and @ITERATION to construct the for the prim path to make sure each card is uniquely named. A material library lop makes the materials, again using @ITERATIONVALUE for the image path, and `@ITERATION` on the prim name so they're split out nicely.
This gallery was more about cards mapped with images, so I need a unique card per workItem, as well as a unique material per workitem. The for loop in Lops exposes more psedudo attributes, @ITERATION and @ITERATIONVALUE, these can be used to ensure everything is split out properly and named correctly. A sopcreate is used to make the card, using `@ITERATIONVALUE` on a trace sop to generate the geo with a bound, and @ITERATION to construct the for the prim path to make sure each card is uniquely named. A material library lop makes the materials, again using @ITERATIONVALUE for the image path, and `@ITERATION` on the prim name so they're split out nicely.
 See the python section below for how to use this tops array via python.
See the python section below for how to use this tops array via python.
Promoting the tops UI on HDAs

Workitem dots in lops? Amazing!
You have a neato tops workflow. It's safely hidden deep down somewhere, but you want to expose this nicely to artists, and have the dots be visible on your parent subnet/hda. What to do?
Once again, Jeffy Mathew Philip to the rescue. Modify parameters (or modify type properties for an HDA), switch to the node properties tab, collapse it all up, then dive down into the TOP network properties section, and find Top network cook controls. Add that to your node, accept, close.
 Now jump to your new top tab, point the 'TOP network' parm to your topnet, and the node will update to show you tops things, and you have buttons to do all the generate/dirty/cook/delete results stuff that you want.
Now jump to your new top tab, point the 'TOP network' parm to your topnet, and the node will update to show you tops things, and you have buttons to do all the generate/dirty/cook/delete results stuff that you want.
 Don't make the silly mistake I did, the parm should point to the topnet, not the scheduler within the topnet!
Don't make the silly mistake I did, the parm should point to the topnet, not the scheduler within the topnet!
Tops and Rop FBX animation output
I was helping batch process some fbx clips from a motion capture session, retargeting them onto the Unreal mannequin. The workflow looks like this in sops:
 The important bit here is the Rop FBX Animation Oututput node at the end. This points to the original mannequin fbx, and inserts the new animation.
The important bit here is the Rop FBX Animation Oututput node at the end. This points to the original mannequin fbx, and inserts the new animation.
Part of this requires knowing the length of the animation, which is available as a detail attribute from the imported mocap data. I figured I could just use an expression to read that onto the rop using the detail() hscript call.
Unfortunately when I then tried to call the rop with a tops fetch node, I got warnings saying that the rop itself can't be driven by a time varying expression, and all the fbx exports were 1 frame long.
The trick is to use the other mode on the fbx rop, to use clipinfo. The configureclipinfo sop uses essentially the same expression, but now means there's no external dependencies on the rop, everything is happy.
None of this really requires a hip example, the meat is in a wrangle to extract the last frame of the fbx (its stored as seconds, so needs to be multiplied by the current fps). The 'd' prefix is because this attribute is stored as a not-often-used dictionary type:
float range[] = d@clipinfo['range'];
i@length = int(range[1]*$FPS);
Then the clipinfo uses the following hscript expression, using a spare input to point back to the wrangle:
detail(-1,'length',0)
Tops extract fps of movie via ffprobe
Download hip: tops_ffmpeg_get_fps.hip
You want a dry boring tops example? Here it is. Might be helpful for using other command line tools you want to interface to tops.
Someone was walking through using the ffmpeg extract images top, and was asked 'how would you get the frame rate of a video to tell ffmpeg what to do?'.
Ffmpeg on most systems will usually have 2 other helper commands installed with it:
- ffplay, a bare bones video player
- ffprobe, return metadata from a video.
Ffprobe will usually just print plain text to the console, but you can also print out formatted as json.
In tops I used a generic generator top and this command (which I got from https://gist.github.com/nrk/2286511 ) :
ffprobe -v quiet -print_format json -show_format -show_streams "`pdginput(0, file/video, 0)`"
If you click the 'show log' link of the workitem, you'll see json results. Great, but then how you do process the result of those logs? To my surprise there's no simple way to do this!
Reading the docs, I found that there's @pdg_log as an implicit hidden attribute, which stores the path to the log. I tried writing that to a tops attribute, but when I tried reading that with a json top it errored saying it couldn't load the file. Ugh.
Instead I went lowbrow and used unix style redirects. Unix will usually just print results to screen, so if you typed
ls
You see the results of that command, but if you want it saved to listfiles.txt, you can do this:
ls > listfiles.txt
So I setup @ffprobejson as a path to write to, and use > `@ffprobejson` on the end of the command to write the json to disk (this also required enabling 'run commands in a system shell' on the generic generator):
ffprobe -v quiet -print_format json -show_format -show_streams "`pdginput(0, file/video, 0)`" > `@ffprobejson`
That file could be read with the json top. Hooray!
The json top extracted the text I wanted ( streams/0/avg_frame_rate ), saved it to a tops attribute, which I then had to do a couple of string processing operations to convert from its odd format of '30/1' to just '30'.
None of this process feels elegant though. If you know a better way, let me know!
Use filecopy instead of redirect
 Download file: tops_ffmpeg_get_fps2.hip
Download file: tops_ffmpeg_get_fps2.hip
Immediately after posting the previous one, I thought of an improvement.
I reverted the generic generator back to its usual settings, kept the @ffprobejson attribute, and put a file copy after it to copy @pdg_log to @ffprobejson. That seems happier, and doesn't involve potentially risky system shell stuff.
Tagging workitems
Get it here: https://github.com/WaffleBoyTom/tops_manual_filtering
Proceduralism is great, until it isn't. Tops gives you all sorts of ways to make workitems, but if you've made 50 rocks, how can you tag the best ones for processing later?
There's nothing built-in for this. Luckily WaffleBoyTom, aka Tom Goffelli has thought of a possible workaround. He's written a hda that lets you tag the current workitem as 'bad', which adds it to a multiparm list, and adds a workitem attribute.
Downstream you can filter by this attribute to split off the bad workitems, and keep working with the good ones.
Strangely I'd come across this problem in a work context, had sent an RFE to sidefx, at about the same time that Tom had been thinking about the same problem and created a prototype.
Would be awesome to have this natively in Tops of course, but great that Tom could get a prototype working so quickly. Killer stuff!
He's got a bunch of great Houdini hdas, tips+tricks on his various outlets, you should go look at them right now. I SAID RIGHT NOW:
https://vimeo.com/waffleboytom
https://www.youtube.com/@waffleboytom/videos
https://github.com/WaffleBoyTom
https://www.linkedin.com/in/tom-goffelli-a07696242/\
Python
Bit of a rubbish topic filter, but the tips section was getting too broad, and I had bits of python code scattered all over the page, thought it best to just collected them all in one place.
Filter by range with python
A workmate wanted to filter to the last 2 items in his workitems.
After 30 mins of swearing I realised I already had a solution further up the page in a non expression, non code way. Partition your workitems so they're 'packed', then immediately unpack them with a workitem expand. It has options for 'first N', 'last N', which is pretty much what he needed.
But hey, we're using Houdini, we're not here for the easy fix!
Say you didn't know that trick, and wanted to use a vanilla filter by range node. This lets you specify the start and end, but has no ability to know how many workitems you have, so you can't easily slice off the last 2 workitems.
It seemed possible that you could use an expression to get the number of workitems being fed to the node, then subtract from that. But how? The docs imply tops attributes are like sops with @pdg_index, @pdg_id etc as built in pseudo-attributes. This page said we should have @pdg_inputsize, but tops would just error when I tried. Surely a @numpt-2 wouldn't be hard to discover?
After much thrashing about, this worked:
len(pdg.workItem().node.workItems)-2
So:
- Create a filter by range.
- Set the mode to 'work item index' (it defaults to filtering by frames)
- control-e/cmd-e on the 2nd parm of the filter range parm
- Set the language to python at the bottom
- Paste in the code, makes sure its a single line (thanks picky python)
- Hit accept
So why this way? Why not hscript? Why not something else?
Tops is mostly python under the hood. It feels silly to use other languages here, plus I need to brush up on my tops python skills anyway.
Further, hscript support for tops is very limited, so python it is.
Several examples in the docs point to pdg.workItem() as a basic building block of python expressions. I had to go fumble in the help to see what could be used from here.
To get to the node that contains the workitem, you append '.node'.
To get a list of workitems for that node, append '.workItems'.
Run that to a len(), and you have what you need.
Tops really needs a cookbook page in the official docs, this was frustratingly hard to discover...
Find text in a workitem attribute with python expressions
You need to get the current workitem, then its attribute, then eval it as a string.
python
dirpath = pdg.workItem().attrib('directory').asString()
if dirpath.find('disp')>-1:
return 1
else:
return 0 dirpath = pdg.workItem().attrib('directory').asString()
if dirpath.find('disp')>-1:
return 1
else:
return 0Alessandro Pepe came up with an interesting middle ground. Create a spare parameter, have that read @directory, then in the main python expression, use self['attrib'].evaluateString() . Better? Not sure. I definitely think tops python could use a nicer shortcut here.
Python script and pdg_input
In a python script top, one of the examples in the drop-down shows you how to get index and name of the workitem:
work_item.indexwork_item.name
Great. So the one you'd most likely need, @pdg_input, that'd be obvious right? No.
work_item.inputResultData[0][0]
Wot? Or you can get ugly and mix your @'s with your python code, but you have to wrap it in backticks *and* in quotes. Ugh.
"`@pdg_input`"
Get modified time of workitem as attribute
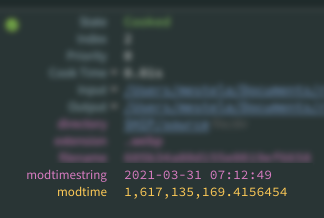 Armed with the above stupid trick, we can do this:
Armed with the above stupid trick, we can do this:
python
import os
modtime = os.path.getmtime('`@pdg_input`')
work_item.setFloatAttrib("modtime", modtime) import os
modtime = os.path.getmtime('`@pdg_input`')
work_item.setFloatAttrib("modtime", modtime)Which is... what? Giant mystery number? It's the number of seconds since the epoch. What? Exactly. Different OS's define 'the start of all time' in different ways, Linux sets it as midnight, Jan 1, 1970. Humans want that in a more readable format, so you'll want to employ the python datetime module:
python
import os
from datetime import datetime
modtime = os.path.getmtime('`@pdg_input`')
work_item.setFloatAttrib("modtime", modtime)
modtimestring = datetime.fromtimestamp(modtime).strftime('%Y-%m-%d %H:%M:%S')
work_item.setStringAttrib("modtimestring", modtimestring) import os
from datetime import datetime
modtime = os.path.getmtime('`@pdg_input`')
work_item.setFloatAttrib("modtime", modtime)
modtimestring = datetime.fromtimestamp(modtime).strftime('%Y-%m-%d %H:%M:%S')
work_item.setStringAttrib("modtimestring", modtimestring)There, a nice giant number that's easy to compare for sorting files oldest/youngest, and a nice string attribute for humans to read.
Create workitems with attributes from python array
Interesting question on the sidefx forum, had a quick play.
Pretty straightforward actually, use a python processor top. A python script top is the simpler node that lets you modify workitems, a python processor top lets you create workitems and other stuff. The example code dropped into the node by default was enough to pull apart and get something working:
python
import hou
paths = [
'$HFS/houdini/pic/butterfly1.pic',
'$HFS/houdini/pic/butterfly2.pic',
'$HFS/houdini/pic/butterfly3.pic',
'$HFS/houdini/pic/butterfly4.pic'
]
for p in paths:
new_item = item_holder.addWorkItem()
new_item.setStringAttrib('texpath', hou.text.expandString(p))import hou
paths = [
'$HFS/houdini/pic/butterfly1.pic',
'$HFS/houdini/pic/butterfly2.pic',
'$HFS/houdini/pic/butterfly3.pic',
'$HFS/houdini/pic/butterfly4.pic'
]
for p in paths:
new_item = item_holder.addWorkItem()
new_item.setStringAttrib('texpath', hou.text.expandString(p))Append a rop composite top, set the input path to `@texpath`, high fives all round.
Using the tops array in python
My initial attempt before talking to Ben and Michael was to use python. It works, but I think pdg_attribvals is easier.
Here's where I got to in a python sop before getting bored and using the other methods. pdg.workItem() gives you the current workition/partition, and pdg.workItem.partitionItems gives you the array of workItems. This means you don't need to the partition trick of attrib promoting to an array, but then requires further python to get the attrib for each workItem. Works, but is a little verbose.
python
node = hou.pwd()
geo = node.geometry()
import pdg
wi = pdg.workItem()
geo.addAttrib(hou.attribType.Point, "image", '')
images = [ x.attribValue('image_path') for x in wi.partitionItems]
for i in images:
point = geo.createPoint()
point.setAttribValue('image',str(i))node = hou.pwd()
geo = node.geometry()
import pdg
wi = pdg.workItem()
geo.addAttrib(hou.attribType.Point, "image", '')
images = [ x.attribValue('image_path') for x in wi.partitionItems]
for i in images:
point = geo.createPoint()
point.setAttribValue('image',str(i))Convert wedgeindex to letters
Interesting question from the sidefx forum. Someone was generating wedges, but wanted the output filenames to be name_A name_B name_C instead of name_1 name_2 name_3.
Python has a chr() function, so give it chr(65), it returns A, chr(66) is B etc. Here's some fiddly python code to put in an attribute create top:
python
num = pdg.workItem().intAttribValue('wedgeindex')
name = pdg.workItem().stringAttribValue('name')
return name+'_'+chr(num+65)num = pdg.workItem().intAttribValue('wedgeindex')
name = pdg.workItem().stringAttribValue('name')
return name+'_'+chr(num+65)Farm
Hqueue
I didn't set it up, no notes to share, but just to say that hqueue and tops play very nicely together. Something immensely satisfying to be able to interactively cook a tops graph, and see it trigger lots of workitem cooks on the farm as fast as you can press shift-v.
Plus the more people who use it, the more people there are to send bug reports to sidefx and help make hqueue even better. 😃
Force python scripts to run on the farm
If you have a python script node, even if you have a tractor or deadline scheduler, it will run in your local houdini session by default.
To fix this, turn off 'Evaluate in process'.
Ensure a rop geometry top sim runs on a single blade
You don't want 240 machines all doing their own run up, that's silly. Go to the 'rop fetch' tab, enable 'all frames in one batch', that'll lock it to a single blade and run sequentially.

Tractor scheduler stuck
Happens <s>too often</s> less often after some fixes from sidefx. Tricks to unstick it in order of least to most annoying:
- Make sure there's no active stuck jobs of yours on the farm, delete 'em all and try again
- R.click on tractor scheduler, 'delete temp directory'
- Select the tractor scheduler, ctrl-x to cut it, ctrl-v to paste it
- Reload the hip
- Restart houdini
- Quit FX
- Quit the industry
Rez and tops debugging
Running this in a python script top to see whats going on with rez and environment values:
vex
print('debug info...')
key = 'REZ_RESOLVE'
print(key+'='+os.environ[key])
print ('')
import pdg
has_tractor = str(pdg.types.schedulers.has_tractor)
print('pdg.types.schedulers.has_tractor: ' + has_tractor)
print ('')print('debug info...')
key = 'REZ_RESOLVE'
print(key+'='+os.environ[key])
print ('')
import pdg
has_tractor = str(pdg.types.schedulers.has_tractor)
print('pdg.types.schedulers.has_tractor: ' + has_tractor)
print ('')Tractor
 Mostly works, the long story can be found below, but here's the summary:
Mostly works, the long story can be found below, but here's the summary:
- Your environment needs access to the python tractor api. If you use rez, make sure to bring in a package for tractor.
- PDG assumes it'll find $PYTHON set correctly. We didn't have this, but even then I found I couldn't use the regular system python, but had to point it to hython ( $HFS/bin/hython )
- If your farm is behind a firewall, make sure your IT department chooses 2 ports you can use, and enter those ports into the callback and relay port fields on the tractor scheduler
- As of 18.0.502 retry support exists on the tractor scheduler, as well as options for better logging.
- Cooking jobs by default expects to connect to your desktop machine to update information, give you blinky lights and dots. This means that if you close your houdini session, the job will stop working on the farm. Call me old fashioned, but that defeats most of the point of using a farm. If you don't want this, use the 'submit graph as job' option at the top of the tractor scheduler, and it will run independent of your GUI session. Getting these to work reliably was problematic for us, YMMV.
Tops and tractor diary
Moving the diary to TopsTractorDiary.
Todo
Some neat ideas for examples/topics from Jeffy Mathew Philip:
- converting between one format to another(like ingesting a kitbash set and spitting out individual alembics, or fbxs or usds) - like building an asset zoo.
- example running the hda processor for poly reduction or geo processing
- using the invoke top for geo processing(can use the top geometry sop)
- more uses of the partitioning tops, eg partitioning a wedged -> substepped simulations to give me the wedges, and then I combine at the end to use the partition by frame to run the correct set of frames