Appearance
Tops and tractor diary
If you want impartial concise PDG advice, stop reading below this line:
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
We have a pretty big farm at UTSALA (about 130 centos machines with 56 cores per machine on average, so about 7000 cores) which is managed through Pixar's Tractor. We'd like to access all that power with PDG.
My aim is to get solid tractor support by August 2020. I'm starting this diary on 2 June so I can keep track of my progress.
Overall config has changed over time:
- Houdini 18.0.481 and tractor 2.3 on day 1
- Houdini 18.0.460 and tractor 2.4 on day 5
Full disclosure; this is opinionated, sweary, lots of my frustration with the process is all recorded here. Things improved substantially by day 4, but there was a lot of angry words and thoughts in the first few days while I reacquainted myself with PDG.
Skip down to HoudiniTops#Working_setup to see the important things that needed adjusting.
Day 1
Local mantra render
/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/mantrarender.hipnc
Setup a rotating pig, light, camera. Made a topnet, mantra top.
Single frame, clicked cook output (little triangle in the top toolbar with an orange bar on it). All works, pretty fast, great.
Set 48 frames locally, clicked render. Can see it slowly chugging away, 1 frame at a time.

Got bored after 7 frames, clicked the red X to kill the job. Houdini froze for a few seconds. It shouldn't.
Can we submit this on the farm? Lets try...
Farm mantra
Put down a tractor scheduler. Have to remember the details, ugh, lucky I wrote these down:
Tractor Server frank.ala.int.uts.edu.au
Port 5600
Tractor user $USER
Service Keys FarmTractor Server frank.ala.int.uts.edu.au
Port 5600
Tractor user $USER
Service Keys FarmAlright, fail right out of the gate, 'cannot find tractorscheduler' fair enough, we have tractor in another rez package, close houdini, launch in a new rez environment that includes tractor this time:
rez-env houdini-18.0 tractor
Hmm, the tractor libraries are 2.2, the webserver reports its running 2.3. Lets see if that raises any issues. Ok, load the hip again, cook the job... it still goes to the local scheduler. Bypass the local scheduler... it still goes to the local scheduler. Can't see any clear place to set the default scheduler. That's dumb.
(Edit: You right click on the scheduler, 'Set as default scheduler'. Still, some visual indicator would be nice.)
Python missing
Fine, delete the local scheduler, try again. Job goes to tractor, instantly fails. Look at the tractor error log:
[2020/06/02 16:43:03 exec failed - program executable not found: $PYTHON
Well that's dumb. This is with the default pdg settings, it should work surely? Had a a look in the terminal that launched houdini:
$ which python /usr/bin/python$ echo $PYTHON
$
Boo, $PYTHON isn't defined. Shouldn't pdg have appropriate fallbacks for that? Swap the python entry on the tractor scheduler from $PYTHON to /usr/bin/python:
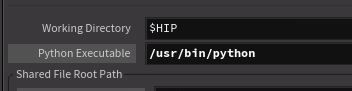
More errors
Alright, job is on the tractor queue, not erroring. Taking a while to kick off though. I want instant status reports, I waste too much time looking at tractor jobs that don't appear to be doing anything.
...and as expected, 20 seconds later, it errors with an inscrutable error code:
PDG_MQ napoleon02.ala.int.uts.edu.au 35355 42098
## Message Queue Server Running
[2020/06/02 16:50:08 kill sweep /J31368/T1/C1.1/139002@snail pid=25991]
[2020/06/02 16:50:08 sent interrupt to pid=25991]`
Traceback (most recent call last):
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/6517/scripts/pdgmq.py", line 683, in `<module>
main()
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/6517/scripts/pdgmq.py", line 676, in main`
args.connectionfile, args.timeout)
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/6517/scripts/pdgmq.py", line 646, in _start_server
relay_server_instance.handle_request()
File "/usr/lib64/python2.7/SocketServer.py", line 276, in handle_request
fd_sets = _eintr_retry(select.select, [self], [], [], timeout)
File "/usr/lib64/python2.7/SocketServer.py", line 155, in _eintr_retry
return func(*args)
KeyboardInterruptPDG_MQ napoleon02.ala.int.uts.edu.au 35355 42098
## Message Queue Server Running
[2020/06/02 16:50:08 kill sweep /J31368/T1/C1.1/139002@snail pid=25991]
[2020/06/02 16:50:08 sent interrupt to pid=25991]`
Traceback (most recent call last):
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/6517/scripts/pdgmq.py", line 683, in `<module>
main()
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/6517/scripts/pdgmq.py", line 676, in main`
args.connectionfile, args.timeout)
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/6517/scripts/pdgmq.py", line 646, in _start_server
relay_server_instance.handle_request()
File "/usr/lib64/python2.7/SocketServer.py", line 276, in handle_request
fd_sets = _eintr_retry(select.select, [self], [], [], timeout)
File "/usr/lib64/python2.7/SocketServer.py", line 155, in _eintr_retry
return func(*args)
KeyboardInterruptWhat the hell? These errors should be better wrapped, I don't have time nor interest to fight through hard to read python tracebacks.
So, some memories from earlier attempts at pdg are coming back; it looks like a timeout error. We run a setup like most studios nowadays, our workstations are in one place, and the farm is firewalled away in a data center. If this is expecting to talk through the firewall, that won't work.
Maybe it'll be happier if I keep it inside the studio, only running on artist workstations? We have a Service Key Expression for 'Studio' to do this.
Try again, immediate infuriating error on the node itself. Middle click, see this:
`Error `
`Failed starting PDG MQ Server`
[`http://frank.ala.int.uts.edu.au:5600/tv/#jid=31369&tid=1`](http://frank.ala.int.uts.edu.au:5600/tv/#jid=31369&tid=1)
`RuntimeError: Failed to connect to PDGMQ: Timed out``Error `
`Failed starting PDG MQ Server`
[`http://frank.ala.int.uts.edu.au:5600/tv/#jid=31369&tid=1`](http://frank.ala.int.uts.edu.au:5600/tv/#jid=31369&tid=1)
`RuntimeError: Failed to connect to PDGMQ: Timed out`Grrr, that sounds like one of these dumb random errors. Bet if I retry a few times, clean local results etc it'll go away.. And no, immediate error. Try reverting the service key expression to 'Farm' as it should be? Nope, error again, fucking hell. Revert to the default 'Houdini'? NOPE, STILL ERRORING.
Restart Houdini? Sure. Annnd same error. Fuck me.
`[2020/06/02 17:17:28 sent interrupt to pid=26769]`
`Traceback (most recent call last):`
` File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/16363/scripts/pdgmq.py", line 683, in `<module>
` main()`
` File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/16363/scripts/pdgmq.py", line 676, in main`
` args.connectionfile, args.timeout)`
` File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/16363/scripts/pdgmq.py", line 646, in _start_server`
` relay_server_instance.handle_request()`
` File "/usr/lib64/python2.7/SocketServer.py", line 276, in handle_request`
` fd_sets = _eintr_retry(select.select, [self], [], [], timeout)`
` File "/usr/lib64/python2.7/SocketServer.py", line 155, in _eintr_retry`
` return func(*args)`
`KeyboardInterrupt`
`[2020/06/02 17:17:28 sent interrupt to pid=26769]`
`Traceback (most recent call last):`
` File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/16363/scripts/pdgmq.py", line 683, in `<module>
` main()`
` File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/16363/scripts/pdgmq.py", line 676, in main`
` args.connectionfile, args.timeout)`
` File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/16363/scripts/pdgmq.py", line 646, in _start_server`
` relay_server_instance.handle_request()`
` File "/usr/lib64/python2.7/SocketServer.py", line 276, in handle_request`
` fd_sets = _eintr_retry(select.select, [self], [], [], timeout)`
` File "/usr/lib64/python2.7/SocketServer.py", line 155, in _eintr_retry`
` return func(*args)`
`KeyboardInterrupt`Leaving this for now. Try creating a new scheduler node when you pick this up again (and also, scheduler is really hard to type).
Try again
Made a fresh tractor scheduler, set the python path, set the Service Key to 'Studio', but importantly this time set ports (these ports had been defined earlier after talking with our IT manager)
Task Callback Port 1996Relay Port 1997
This time, woo, blinky lights straight away, much rejoicing in the streets.
Submit graph as job
Ooookay, it's all coming back; this current mode is communicating to my local box to do blinky lights. Cute, but we won't be using that in production, that's what a farm manager is for. Lets try the headless mode, 'Submit graph as job'. It's on the top of the tractor scheduler.
And of course, errors again:
*** Starting:/mnt/ala/software/ext_packages/houdini/18.0.481/install/bin/hython /mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/16363/scripts/top.py --report none --hip /mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/mantrarender.hipnc --toppath /obj/topnet1Running Houdini 18.0.481 with PID 52963Loading .hip file /mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/mantrarender.hipnc.Given Node 'topnet1', Cooking Node 'ropmantra1'Finished CookWork Item States:
From node tractorscheduler1:Could not find scheduler type "tractorscheduler"
** Finished with Exit Code 1
Cannot find scheduler? Ugh. Maybe this is why we needed to use hython when I was testing earlier in the year. Right, changing the python executable again...
Python Executable $HFS/bin/hython
Nope, after an annoyingly long pause, in an error/restart cycle. Same error:
From node tractorscheduler1:Could not find scheduler type "tractorscheduler"
Sigh
From memory we had to now double check the environment the farm job is being spawned in, a toggle either HAD to be enabled or HAD to be disabled. Lets have a look...
Inherit local environment
Ah, found it, second tab on the scheduler, 'inherit local environment'. It's off by default, have enabled it, resubmitting.
Woo, subjobs are happening! But boo, a handful of jobs are seemingly hung:
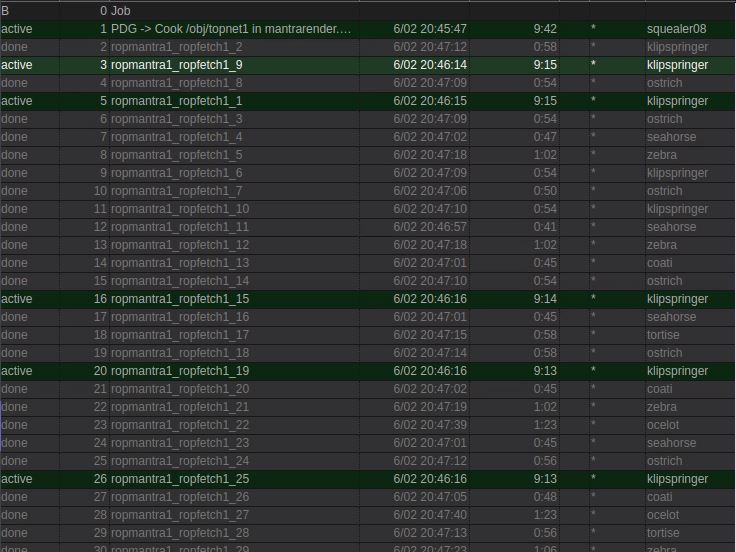
I let it run, it did eventually finish, 15 minutes later. But look, all those slow jobs are on the same machine. Hmm. A dud studio box maybe? Lets try this again with the farm pool.
Using farm boxes
Swap the service key to 'Farm', lets see what happens. Handily the r.click 'delete this nodes results from disk' option works with the mantra top, so I delete all the frames, and will watch them be recreated on the next run.
Submit, see it appear on tractor, wait 30 seconds and.... complete? What? Where's the sub jobs? Where's my frames? Looking at the error log:
*** Starting:/mnt/ala/software/ext_packages/houdini/18.0.481/install/bin/hython /mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/16363/scripts/top.py --report none --hip /mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/mantrarender.hipnc --toppath /obj/topnet1Running Houdini 18.0.481 with PID 2662Loading .hip file /mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/mantrarender.hipnc.Given Node 'topnet1', Cooking Node 'ropmantra1'PDG Callback Server at squealer15.ala.int.uts.edu.au:1996Finished CookWork Item States:ropmantra1_ropfetch1_1 workItemState.CookedCacheropmantra1_ropfetch1_2 workItemState.CookedCacheropmantra1_ropfetch1_3 workItemState.CookedCacheropmantra1_ropfetch1_4 workItemState.CookedCacheropmantra1_ropfetch1_5 workItemState.CookedCacheropmantra1_ropfetch1_6 workItemState.CookedCacheropmantra1_ropfetch1_7 workItemState.CookedCacheropmantra1_ropfetch1_8 workItemState.CookedCache
...and so on for all 48 frames. What the hell? Ugh, lets do the usual scrub dance. Delete temp files from the scheduler, save the hip, dirty the mantra top, try again.
Oh good, the same behavior. At least it finished in 18 seconds this time. Ugh, will restart houdini, try again.
And yep, same after a restart. Will try swapping the Service Key back to 'Studio'.
FFS. No. Swap back to studio, delete temp folder, its now stuck in this state. Goddamnit PDG, why?
~ Time passes ~
Gnnnng, looked on disk, the frames were there. Deleted, rerun as a studio job, now they're rendering once more. FFFFFFFFFFFFFUUUUU
Ok, will let this run, then try the Farm service key again.
(Edit: As you'll read in a bit, this is expected behavior. 'CookedCache' means 'I found files on disk, so I won't bother spinning up the job again.')
Submission string now broken
No wait a sec, all the jobs are repeatedly failing. But... it just worked? Like 10 minutes ago??
Look in the error logs again, can see this error on all jobs:
usage: pdgjobcmd.py [-h] [--setenv SETENV SETENV] [--preshell PRESHELL] [--postshell POSTSHELL] [--prepy PREPY] [--postpy POSTPY] [--norpc] [--echandleby ECHANDLEBY] [--eccustomcode ECCUSTOMCODE] ...pdgjobcmd.py: error: argument --setenv: expected 2 argument(s)
Wat? The command string that worked before is now broken? BUT WHY?
Ok, more memories coming back; our cg sup Dan had an email back and forth with sidefx about this, pointed to a one line fix in one of the pdg python scripts, gotta find that email now...
Ah bollocks. That patch Dan suggested is now part of the install. Good I guess, but that means I don't understand why this is failing again. Try turning off that local environment toggle maybe?
No, back to the 'cannot find tractorscheduler' error. Ok fine. Time to read my earlier notes more closely.
~ More time passes ~
Ah yes, I can see that we were doing something specifically for the environment:
Env Keys rez-pkg=houdini_pdg
Lets try that, and leaving 'inherit local environment' off, I'm sure Dan said that was bad news.
GASP
Render worked! With the farm blades! OMG!
Working setup
So lets recap:
- Python Executable should be $HFS/bin/hython. $PYTHON isn't defined. /usr/bin/python didn't work.
- The rez environment required houdini and tractor. eg 'rez-env houdini-18.0 tractor' as a minimum, but I think our launcher houdini environment has all this included by default anyway.
- Callback and relay ports are 1996 and 1997. Our firewall and the datacenter firewall has enabled only those to get though.
- Dan's environment bug fix has been included by Sidefx. No need to patch manually.
- Environment key is 'rez-pkg=houdini_pdg'. Without this the headless mode can't find the tractor python libraries
- Inherit local environment should be disabled - otherwise the farm environment is a horrible hodgepodge of setenvs and weirdness.
Right! Time to try some more complex setups.
Sim then mantra
Right, emit lotsa particles, file cache, merge with original shape:
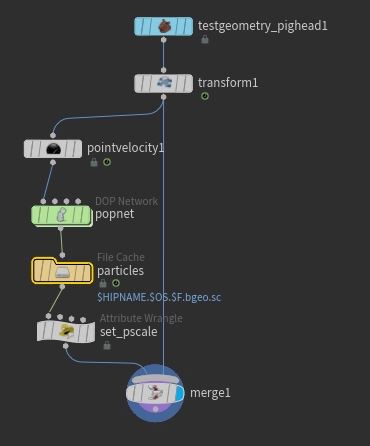
To run that file cache sop from tops, I'll use a fetch. Note a few things here; the framerange is set on the fetch (it just ran a single frame if not explicitly set), it's set to run 'all frames in one batch' (its a sim, you can't share this among machines), and the waitforall means the mantra render has to wait for all 48 frames of the cache to be finished before it starts. It also means that the mantra job sees a single upstream dependency, so will only render 48 frames. Without the waitforall, each frame in the cache becomes an upstream dependency, meaning you trigger the 48 frame mantra render 48 times, you don't want that!
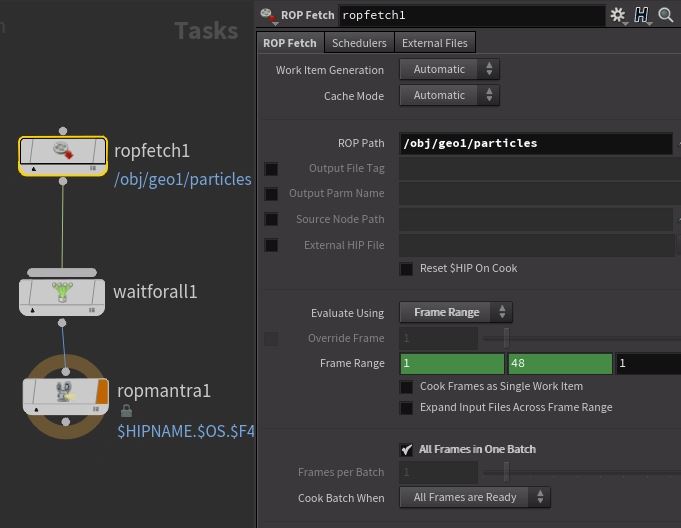
To my joy this worked without fuss both locally and on the farm. Feeling cautiously optimistic about pdg now...
Chaser mode with map by index
An issue with this setup is the mantra jobs have to wait for the entire cache to finish before they start. Ideally as soon as frame 1 of the cache is ready, frame 1 of the mantra render can start, frame 2 of the cache is ready, frame 2 of the mantra render can start etc.
The farm back at Animal Logic had 'chaser mode', which did exactly this, I assume that's possible here. Looks like it's just a matter of replacing the waitforall node with a mapbyindex. After making that change I can see tractor go into a pleasing frenzy of firing off mantra jobs as fast as cache frames are ready.
Interactive farm mode
Out of curiosity I went back to just running the job from the GUI, but using tractor. All works as expected, handy for interactive sessions I guess, and everyone loves blinkylights.
But AHA, on a resubmit I saw the error I hated from the last time I was testing a few months ago: an instant red error on the tractor scheduler, 'connection refused'. Fixed by right clicking on the scheduler and clearing its temp directory. It should be smarter than this.
Hmm, and watching the job run now with a heavier cache, the chaser mode thing seems to wait quite a while before starting. Why is that? And when it started, it started frame 20 first, then 22, 23, 24, 25, and eventually decided to jump back to frames 1, 2, 3. Odd.
And double hmm, I was admittedly getting cocky, and scrubbing the image sequence in cops as it was rendering, and crashed houdini before the job finished. Was curious to see what would happen on tractor. Interestingly the frames completed and were marked as 'done', its just the MQ job that keeps idling. That should silently kill itself if it can't talk to the gui session anymore, it's soaking up a blade.
(Edit: ah, it did kill itself after 13 minutes, well done.)
Anyway, look! Renders! Worth it right?

Day 2
Submit from full production environment
Before getting too ahead of ourselves, need to make sure this all works in our full production environment. Will try Houdini from the Shotgun launcher, run this hip, see what happens.
Hmm, job sent to the farm, similar 24 second startup, then 1 second of 'I've done all the jobs, thanks bye', no creation of sub jobs. Will try clearing the scheduler temp folder, try again.
Nope, still insta-complete. Check for files on disk... and yes, files are there. I guess that's a good feature, but then the matching 'delete files on disk' should work for all nodes, not just for mantra tops, and not just for if the node has already been dirtied+cooked so it knows what to look for. Maybe also a better warning in the logs, like 'result exists, skipping item', this log entry is too vague:
ropmantra1_ropfetch1_44 workItemState.CookedCache
Anyway, cooking now.
Single frame failed and cant be re-queued, needs full resubmit
Some time has passed, all frames have cooked bar frame 47. But the parent MQ job has finished. That's no good. A resubmit on that task doesn't work, as it can't connect to the MQ. Basically this is a failed task that will require a resubmit from houdini. A render farm shouldn't act like this. How did the parent MQ task complete when all the child processes weren't complete?
Had a look at the logs, yeah, the MQ is aware of it, but didn't do anything about it:
ropmantra1_ropfetch1_45 workItemState.CookedSuccessropmantra1_ropfetch1_46 workItemState.CookedSuccessropmantra1_ropfetch1_47 workItemState.CookedFailropmantra1_ropfetch1_48 workItemState.CookedSuccess
Resubmitted from Houdini, and yes, the job was smart enough to only create a single subjob for frame 47. Good I guess, but not an ideal solution. Is that a setting we can change to auto retry x times? If This PDGMQ is going to become a proxy farm manager, than we need farm style controls, off the top of my head:
- Number of retry attempts
- Max timeout
- Memory requirements? Ie, our our farm tries to pack at least 4 jobs per blade (we have multicore blades, this makes sense), but be able to say 'no, this sim requires a single blade, no sharing'
- Max timeout compared to neighbor frames? Ie, if a single frame is 30% above the time of the surrounding frames, assume its sick, kill it and restart on another host?
FFmpeg crash
Was chatting about ffmpeg at the time, thought 'oh yeah, pdg can do that.'
Appended an ffmpeg top, r.click to dirty and cook, Houdini insta-crashed without warning. Got this error from the terminal:
/mnt/ala/software/ext_packages/houdini/18.0.481/install/bin/houdini-bin: symbol lookup error: /mnt/ala/software/ext_packages/houdini/18.0.481/install/bin/../dsolib/libHoudiniPDG.so: undefined symbol: _ZN3tbb10interface78internal20isolate_within_arenaERNS1_13delegate_baseEl
Thanks a bunch PDG.
Anyway, lets have a gif update to lighten the mood:
Such colours!
Lops and USD rops
Moving on! Lets try and write out a USD cache.
Urk, library conflicts with USD, that's no good. Not pdg's fault, will rollback to the minimal houdini+tractor environment for now.
Oh look, a USD rop exists as a Top node. Handy. That works, but to fold in with our existing workflow I'd like to fetch a usd rop that lives in a lop network. Tried that, it errors. Will have to dig into that.
~ Time passes ~
Right, partially my mistake, but partially pdg poor error reporting. The fetch looked like it errored, and was generating a little blinkylight for every frame, when really it should only be a single job. That said, middle clicking revealed no error logs when run through the local scheduler. On a whim I went to look in the output folder, and the USD file was there. Load it in lops, the file was fine.
Ran the same job through tractor. It took a silly amount of time to spin up the single job (around a 30 second delay, it should have spun up in less 5 seconds on an otherwise empty farm), worked for a bit, then errored. Again, the output usd was fine. Looking at the error logs on tractor, could see the issue:
PDG: Setting batch sub index to 4620:44:34 PDG_START: ropfetch10_5;4620:44:34 PDG_RESULT: ropfetch10_5;46;u'__PDG_DIR__/geo/usdsubmit.flippy.usd';;020:44:34 PDG_SUCCESS: ropfetch10_5;46;0.0ERROR: The attempted operation failed.Error: Layer saved to a location generated from a node path: /mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/geo/obj/geo1/OUT.usdPDG: Setting batch sub index to 47
It's complaining that I either haven't set a layer save path for my sop import, or I haven't flattened all layers. Set the Lop rop to flatten all layers, run again, it works without error.
A few things that need fixing here:
- The amount of jobs being generated should either better reflect the output (a single item), or it should update the blinkylights as each frame is processed.
- That error should probably be a warning
- That error should be visible from the local scheduler. Ironic that I'd expect to use the local scheduler to debug stuff, instead here I got more information from the farm scheduler!
(Edit: There IS a way to see better errors locally, keep reading...)
Renderman
Ventured a little further with my rez environment, this time bringing in renderman for houdini. We have a cryptically named rez package for this:
rez-env houdini-18.0 tractor renderman_for_houdini
Start Houdini, make a renderman rop, camera, integrator, make a pxr material builder CLICKBOOM instacrash. Try again, same. So this test is dead in the water. From experience I fear that the newer build of Houdini (18.0.481) isn't compatible with our slightly older build of renderman (23.2). Trying again in a more clean env to be sure:
rez-env houdini-18.0 renderman_for_houdini
Nope, crashes too. Uggh fine, lets rollback to the previous version of Houdini:
rez-env houdini-18.0.391 renderman_for_houdini
Yaaay, no crash when making the pxr material builder! But lets hope the recent burst of under-the-hood fixes to pdg are in this build of Houdini...
Ok, so rubber toy, material, integrator, camera, light, rop, render, woo. Close image viewer, houdini crash. Shake fist, restart, render a single exr from the ris rop, confirm it appears on disk.
Create a topnet, stick with local scheduler for now, fetch the ris rop, delete the exr on disk, cook, wait 10 seconds, error.
Ohhh, I just remembered that little status/log thing in the top right of tops... could that have an error log? Click it, click the job.. yes! Proper log!
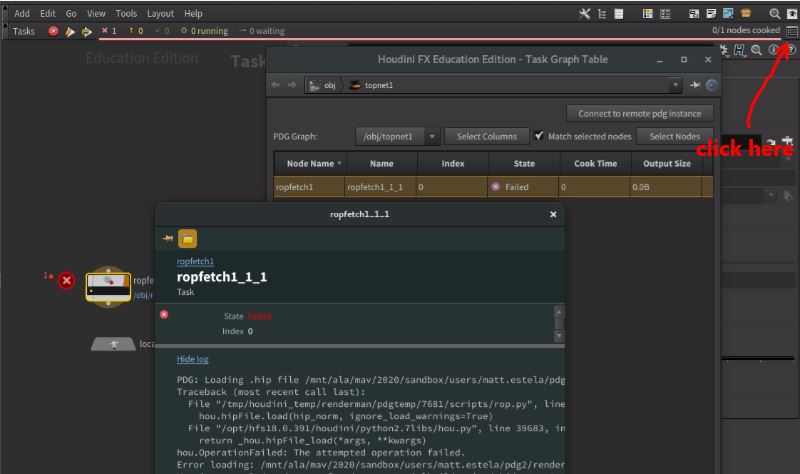
So, what are these errors then?
Warning: Bad node type found: pxrmaterialbuilder in /obj/matnet1.Error: Bad parent found (parent is not a network): obj/matnet1/pxrmaterialbuilder1/output_collect.init. Bad parent found (parent is not a network): obj/matnet1/pxrmaterialbuilder1/output_collect.def. Bad parent found (parent is not a network): obj/matnet1/pxrmaterialbuilder1/output_collect.parm.
Oh dear, those paths don't look right. missing the first slash? Feels like a bug, but for now lets try moving that materialbuilder network back to the standard /mat location.
Nope, complaining about that location too:
Warning: Bad node type found: pxrmaterialbuilder in /mat.Error: Bad parent found (parent is not a network): mat/pxrmaterialbuilder1/output_collect.init. Bad parent found (parent is not a network): mat/pxrmaterialbuilder1/output_collect.def. Bad parent found (parent is not a network): mat/pxrmaterialbuilder1/output_collect.parm.
Maybe there's some options on the ris rop to change how its writing its data out? Hmm, nothing leaps out, nor anything on the local scheduler either.
Probably worth hitting the forums... And yes, can see someone with a similar error in June last year, but that was with HQueue, a repro was sent, Pixar acknowledged it, but no fix. And found a post on the sidefx forums about redshift, someone blamed the bad environment, but in this case I know this render worked from rops. Hmm.
In fact, just went and confirmed it, put everything back in a mat subnet, changed the material and light colours to prove it wasn't just a lucky thing applying default materials, and yes, it's definitely rendering correctly from rops, but is malformed via tops. Gonna post this one to sidefx: https://www.sidefx.com/forum/topic/73982/?page=1#post-312651
Day 3
Renderman fix
Hooray, Chris@sidefx got back to me very quickly, pointed out that its fixed in the 18.0.481, but for older builds you can force HOUDINI_PATH into the pdg environment. On the local scheduler, last tab, do this:
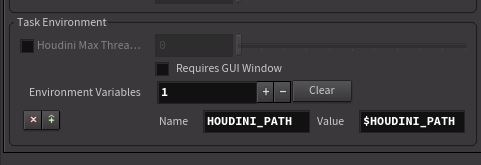
A single image renders! Hooray!
Set it to 10 frames locally, they render! Double hooray!
Try and fire up the tractor scheduler! Oh no! Errors! "Could not find scheduler type 'tractorscheduler'" Fark, seems like doing stuff in latest, then moving back to 391 has broken stuff. So again, at an impasse; can't use latest houdini cos it doesn't work with old renderman, can't use old houdini cos it doesn't work with the tractor scheduler. Ugh.
Fine, time to talk to IT, see if we can update renderman.
Updated renderman more crashes
Well, got the update, great. But RM23.3 and H18.0.481 crash as soon as I try to create a pxr material builder node. Sigh. Reported to Pixar.
I guess I can continue the tests without. Lets try:
Generate a renderman image sequence on the farm
10 frames, running through tractor. And... nothing? Farm seems to have worked fine, jobs completed successfully, but there's no images being generated. Try again with a local scheduler to confirm...
Yep, works fine locally. Crap. Try a 'submit as job' farm session?
Nope, that doesn't work either. Double crap. Why would the tractor scheduler behave different to a local scheduler in this case? Just noticed the 'output parm name' parameter, maybe that has to be set? The renderman rop uses ri_display_0, have keyed that name in, running again.
Hmm, still no images, but more interesting output. On the first run, this is the last line of the logs for a frame:
16:23:04 PDG_RESULT: ropfetch1_6_2;-1;u'__PDG_DIR__/renderman_pdg_v02.ris1.0006.rib';;0
And after I set the output parm name:
16:42:26 PDG_RESULT: ropfetch1_6_4;-1;u'__PDG_DIR__/render/renderman_pdg_v02.ris1.0006.exr';;0
Progress? But what is PDG_DIR set to? Earlier in the logs in the argv dictionary, can see this:
"PDG_DIR", "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2
So that, combined with the earlier path, should be correct. But still nothing there. Unless PDG_DIR is valid and PDG_DIR is blank? Dunno, have asked on the forums again.
Renderman farm renders working
Woo! After posting on the forum I did a little investigating; turns out the rez package we're using for the farm (houdini_pdg) had some hardcoded versions, tsk. One of those was renderman 22, boo. Doing a hack job of setting the package to just houdini_for_renderman got renders working again.
That said, ideally what we have the GUI session using, should be baked and replicated on the farm. That's what I thought the 'inherit local environment' toggle was for, but every time I try it I can see a ton of stuff vomited into the job argv dictionary, but renders fail anyway. More investigating required there too.
Are they working?
As a final test before bed i put 240 frames on (so far I've only been testing batches of 10, 20, 40 frames). Saw a ton of blinkylights start, very exicting, first few frames complete in 20 seconds (its a simple pig with a light), great.
But then... nothing? It's now 15 minutes later, no more frames have completed, all the logs for all the frames aren't doing anything. That's not a good sign.
Ohhh.... why has a handful of blade got each got 30 frames assigned to it, all apparently running simultaneously? Even with a simple render, that can't be good.
That's what the at least/at most slots are for right? Setting both to 1, and then 4, still seems to load up single blades with 30 frames.
Heh, its so late, but couldn't help one more try; setting 'max active tasks' at least limited the total number, which seemed to distribute better. Was still getting sick jobs, but turned out to be a single machine, poor little box with 16 cores, 16gb ram, compared to the other much beefier machines. Removed it from the pool (I think), resubmitted, couldn't connect, delete temp folder, resubmit, timeout, delete temp folder again, resubmit, finally went through.
What should have taken 2 mins took 30 mins of head scratching, then another 15 mins of resubmitting failed frames. Still, progress!
A few things to pull apart tomorrow.
Day 4
Tractor slots
Had a chat with our sysadmin, got some clarity. 'Slots' equates to 'cores'. Our farm is running 56 cores on most of our blades, so if I want to ensure only one job is run per blade, I can say 'at least 56 slots, at most 56 slots'. By running with the default of 1 and 1, pdg and tractor assumed it can assign one job to each core, meaning I could have fired up 56 renderman jobs on a single blade in a worst case scenario.
Feels like I'd probably want to set something like 25/56 as the at least/at most, so it packs 2 jobs per blade, that feels appropriate. Can you do this per task? Ideally you'd want a single threaded sim to not be so grabby, they don't scale to multiple procs very well, but let things like renderman go all multicore. Hmm.
Workflow for dropped frames
I setup a similar test to earlier with pops+disk cache, and in pdg a fetch to run the cache, map by index, fetch for renderman. I know that pdg is smart enough to detect files on disk and won't generate jobs for those frames. So this is getting smoother, but its not perfect:
- Submit the job
- Wait until its done, see that 230 frames worked, 10 failed. I know I can't click resubmit in tractor on those failed jobs, as the MQ job has already completed, so they can't get the info they need to run.
- R.click the scheduler, delete temp files, cook again.
- Often it fails cos it can't submit the job to tractor. Shrug.
- R.click the scheduler, delete temp files, cook again.
- This works, only 10 jobs appear on tractor, perfect
- Look again in a few minutes, 9 frames done, 1 failed. Swear.
- R.click the scheduler, delete temp files, cook again. Error, can't submit to tractor again.
- R.click the scheduler, delete temp files, cook again. Works, job is complete.
Clearly a lot of that should be automated. Stuff to ask about.
Submission is getting flakey
Now about 2 out of 3 attempts to cook and send a job to tractor don't appear, or it starts, but only the MQ job appears, and it can't communicate back and forth to start the sub-jobs. It shouldn't be this random.
Submission is getting really flakey
Either pdg is deeply broken, or our setup is deeply broken. 10, 20, 30 frames at a time is fine, but this should be able to scale up. I've submitted 5 times now, the system seems to keep losing the connection to the MQ job, so things just start hanging and timing out. Very frustrating.
For now I've limited the max active tasks to 60, lets see if that behaves better.
Hmm, no, still seems to be hanging. Might be time to try that option for more verbose logs.
Tried again with a limit of 30 active tasks, that seems to be calming things down. Ok in the short term, not viable in the long term.
Risking 40 active tasks now... Yeah that's not going into a zombie state either, 10 frames dropped out of 240, second run got those last 10.
Have a gif.

A big sim
Single box, run on the farm in headless mode, that should be ok right?
Made a pyro solver sim running into a disk cache, and a mantra node. Have to use mantra until I can get a fix for the pxr material builder stuff.
To my joy it pretty much works as expected, fetch for the disk cache with 'all frames in one batch' enabled, mapbyindex, fetch for mantra.
Another annoyance; once the tractor scheduler thinks there's an error, it can't be removed. Even after running the job a few times, it basically stays in an error state for the rest of the session.
Oh, got a fix for the rez package stuff from Naomi! I want to specify multiple rez packages for the farm to use, but
rez-pkg=houdini-18.0 tractor renderman_for_houdini
didn't work. Naomi found that I have to call it in another way, rez-pkgs. Classic, like detail vs details in hscript.
rez-pkgs=houdini-18.0 tractor renderman_for_houdini
Interestingly I'm running with no max limit here, and I have 190 simultaneous jobs, seems to be ok so far. Maybe the other issues with renderman are license contention?
Ah, asked our sysdadmin, no, we're fully licensed up (thanks academic pricing!)
~ Time passes ~
Nope, running 'unlimited' with mantra also gets the odd hangs. If I limit to frames 1-10 its fine. Try 1-240 with a max limit of 60 seems to be ok, so there definitely appears to be a link between too many concurrent jobs and things hanging.
And also no, rez-pkgs didn't work either. Oh well.
Still, a gif! 2.3 million voxels on average, comfortingly calculated somewhere else.
 pyrosim.hipnc
pyrosim.hipnc
Summary so far
- RFE - visual indicator for which is the default scheduler. orange output circle?
- RFE - default python should have fallbacks, or just use hython
- RFE - errors should be better wrapped, allowing vanilla tracebacks to bubble up is hard to read, hard to debug
- RFE - better preflight warnings? eg 'tractorscheduler library not found'?
- BUG - inhert local environment doesn't seem to work like expected. It should be my local envrionment, baked to the farm right? If so, why do renders fail?
- RFE - potential preflight to warn on fetch tops 'hey this is a file cache, if this is after a sim you want to turn on all frames in one batch'
- BUG - 'cook output node' twice will fail 99% of the time, MQ 'connection refused' or similar. R.click and 'delete temp directory' on tractor scheduler fixes most times, but this should be automatic
- RFE - option for timeout limit on MQ killing itself if it can't talk to the artist machine, 15 mins is too long to hog a blade on a busy farm.
- BUG - 'delete files on disk' doesn't work for fetch nodes linked to file cache sops
- RFE - the log for 'workItemState.CookedCache' isn't clear... something like 'output exists, skipping recook'?
- RFE - MQ should resubmit failed items. Someone said it used to do this, it's not atm.
- RFE - Tractor Scheduler needs options to control retry attempts, timeout limit. Be smart? look at average of frames around it?
- RFE - Tractor Scheduler option for memory requirement for a job, 'this flip sim needs 128gb ram', or is that expected to be handled by service keys?
- BUG - ffmpeg top crashed houdini hard, that's poor behavior.
- RFE - USD Rop, 'Error: Layer saved to a location generated from a node path' should be a warning, its non fatal
- BUG - more than 60 mantra jobs at once, or 40 renderman jobs at once hangs forever on the farm, no warning, no timeout.
- RFE - set tractor options per top node. Eg a flip sim requires a blade to itself, all the ram, some procedural rock generators can pack 16 items to a blade, a renderman render might pack 2 items to a blade. Right now its all set on the scheduler. Having multiple schedulers with different options feels silly.
- CHAT - workflow at the moment poor; submit, wait, clear temp, resubmit to catch errored frames, repeat until all frames are done
- BUG - once the tractor scheduler gets an error badge, it stays there, can't be reset
Day 5
Renderman and production builds
Was told that Renderman will only support production builds, annoying but understandable. Latest production build is 18.0.460, something broke around 18.0.463, latest daily build is 18.0.491. Not much that can be done really. Installed 460, rez'd with the following:
rez-env houdini-18.0.460 renderman_for_houdini tractor
Made a pxr volume material, no crash! Sent a render to the farm, all works as expected, great. Still limiting to max 30 jobs for now. Luckily in this case it renders in about 20 seconds a frame, so it came off the farm pretty quickly, no errors.
 pyrosim_prman.hip
pyrosim_prman.hip
Tractor 2.4 update
Taking advantage of a quiet period our sysadmin updated the farm to tractor 2.4. Ran the pyro renderman test, all works fine.
Hoped I could run without max limit, but unfortunately unleashing 200+ frames simultaneously still causes frames to never complete, and the overall job has to be killed.
Day 6
Submitted all the above bugs and rfe's to sidefx, something cathartic about that. Hoping that a bunch will be user error on my part!
FFmpeg again
Tried again and it worked which is great, but it required a few changes.

The ffmpeg top needs to know a few things:
- what part of the upstream nodes are making images
- what the location of those images are
- that the images are bundled into a single unit of work.
The first is handled with tags. Top nodes can name their output(s), in this case the ffmpeg top expects the images to have a 'file/image' tag. On the fetch top for renderman rop enable 'output file tag' and set it to 'file/image'
To know what file name to put in that tag, enable 'output parm name' and set it to 'ri_display_0'. This is the parameter on the ris rop where the image path is set. Note that when I tried this again in a fresh file, it was just ri_display, no _0 suffix, be careful!'
To bundle all the frames into a single unit, use a waitforall top.
A last specific thing for our setup, ffmpeg didn't understand the '-apply_trc' option, so I disabled it.
Fix for delete files on disk and tractor fails on every second attempt
I revisited the issue where r.clicking and deleting results on disk didn't work for fetch tops. On closer inspection it seemed to be ok but narrowed it down to a fetch pointing to a renderman rop.
Getting ffmpeg to work gave me clues to what was happening here, and also explained some other odd behavior in the early days. It looks like the sidefx native rops/tops know what 'output file tag' and 'output parm name' should be. As such you can middle click on a completed frame blinklylight and see it knows what the output is.
If you try the same with a fetch pointing to a renderman rop, it points to a rib file instead. The delete function must be deleting those things instead, so the images remain. Set the output parameters correctly, it works.
Sidefx confirmed the bug with tractor failing on every second submission, it'll be fixed in 18.0.496.
Day 7
Got a few more answers from sidefx, bless 'em:
USD layer error: Wont Fix
USD Layers without a save path will remain an error, but you can stop the error generating on the USD ROP/TOP by disabling Extra files-> Error Saving Layers With Implicit Paths.

Per TOP scheduler overrides
Can be done by adding spare parameters, see
https://www.sidefx.com/docs/houdini/tops/schedulers.html#jobparms
(I think these should be added to all TOP nodes by default, but that's me)
Tractor memory limits - thats a tractor problem
That information isn't exposed via the tractor API, so yes, the only way would be to use named pools.
Day 8
Retry support!
18.0.502 adds retry controls on the tractor scheduler! It's also much more stable in terms of being able to send jobs repeatedly to the farm, and I don't have to keep manually deleting temp files, making the whole process much smoother.
The retry commands are exposed on the 'job parms' tab of the scheduler:
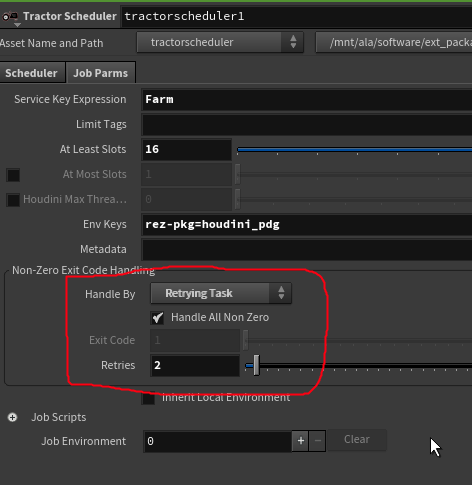
Amusingly I couldn't make it fail hard to see if the retries worked. Well, except for one case, the last frame of a 240 frame mantra sequence refused to render. Had a closer look, it was trying to load frame 241 of the sim cache. This confused me until I remembered I'd turned on motion blur. To get the correct time samples it has to load the next frame. Dur me.
Submit graph as job not working again
Realised I hadn't tried that in a while. Submitted, farm thinks for a little bit, returns its all complete. Look in the logs, can see it now tells me with a pleasingly verbose log that it thinks everything is cooked:
ropfetch1_192 workItemState.CookedCache (Expected output files found, did not recook)ropfetch1_193 workItemState.CookedCache (Expected output files found, did not recook)ropfetch1_194 workItemState.CookedCache (Expected output files found, did not recook)
Fine, delete all the results on disk, submit and... oh, the same. But if I submit from within the GUI, renders start as expected. Hmm.
More errors with submit graph as job
If I just submitted the mantra job and left the sim cache, getting lots of failed frames that don't appear to be retrying. Errors all of this format:
Traceback (most recent call last):
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/59537/scripts/pdgjobcmd.py", line 210, in <module>
main()
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/59537/scripts/pdgjobcmd.py", line 99, in main
execStartCook()
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/59537/scripts/pdgcmd.py", line 443, in execStartCook
_invokeRpc(s, "start_cook", item_name, theJobid)
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/59537/scripts/pdgcmd.py", line 267, in _invokeRpc
return _invokeRpcFn(fn, fn_name, *args)
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/59537/scripts/pdgcmd.py", line 273, in _invokeRpcFn
return _invokeXMLRpcFn(fn, fn_name, *args)
File "/mnt/ala/mav/2020/sandbox/users/matt.estela/pdg2/pdgtemp/59537/scripts/pdgcmd.py", line 346, in _invokeXMLRpcFn
raise RuntimeError(msg)
RuntimeError: Failed RPC: start_cook ('ropfetch1_213', '31563')
12:04:47 PDG_START: ropfetch1_213;-1
12:04:47 Socket Error: [Errno 111] Connection refused. Retry 1/4
12:04:47 Socket Error: [Errno 111] Connection refused. Retry 2/4
12:04:47 Socket Error: [Errno 111] Connection refused. Retry 3/4
12:04:47 Socket Error: [Errno 111] Connection refused. Retry 4/4
12:04:47 Socket Error: [Errno 111] Connection refused
12:04:47 Failed RPC: start_cook ('ropfetch1_213', '31563')
Todo
more heavy simulations (lets try a big pyro sim!)USD rops for cachesrenderman renderssimple image processing setup - with option to limit to first 5 images while testing- USD renders
- shotgun based things
- distributed sims? i see a tempting 'distribution' section on the bottom of the fetch top...
- push these changes into the ALA FX container -->